FUJIFILM IWpro
Intelligent Assistantオプション
アナリティクス使い方
ガイド
3.学習する

学習する方法を知る
AIモデルを学習させるには、業務目的に適した分析タイプを定め、
分析タイプに応じた学習用データを用意する必要があります。
分類・データマッチング・入金請求突合
学習してAIモデルを作成する
アナリティクスに学習用データを入力し、分析タイプに応じて学習に必要な設定をします。
入金請求突合
- 入金データ、請求データの双方で、共通キー項目(データを紐づけるための共通の項目)を選択します。
- 入金データの、識別項目(※) 、金額、名称、日時に対応する項目を設定します。
- 請求データの、金額、名称、日時に対応する項目を設定します。
※入金データに請求データと紐づけるための共通キー項目を含める場合のみ
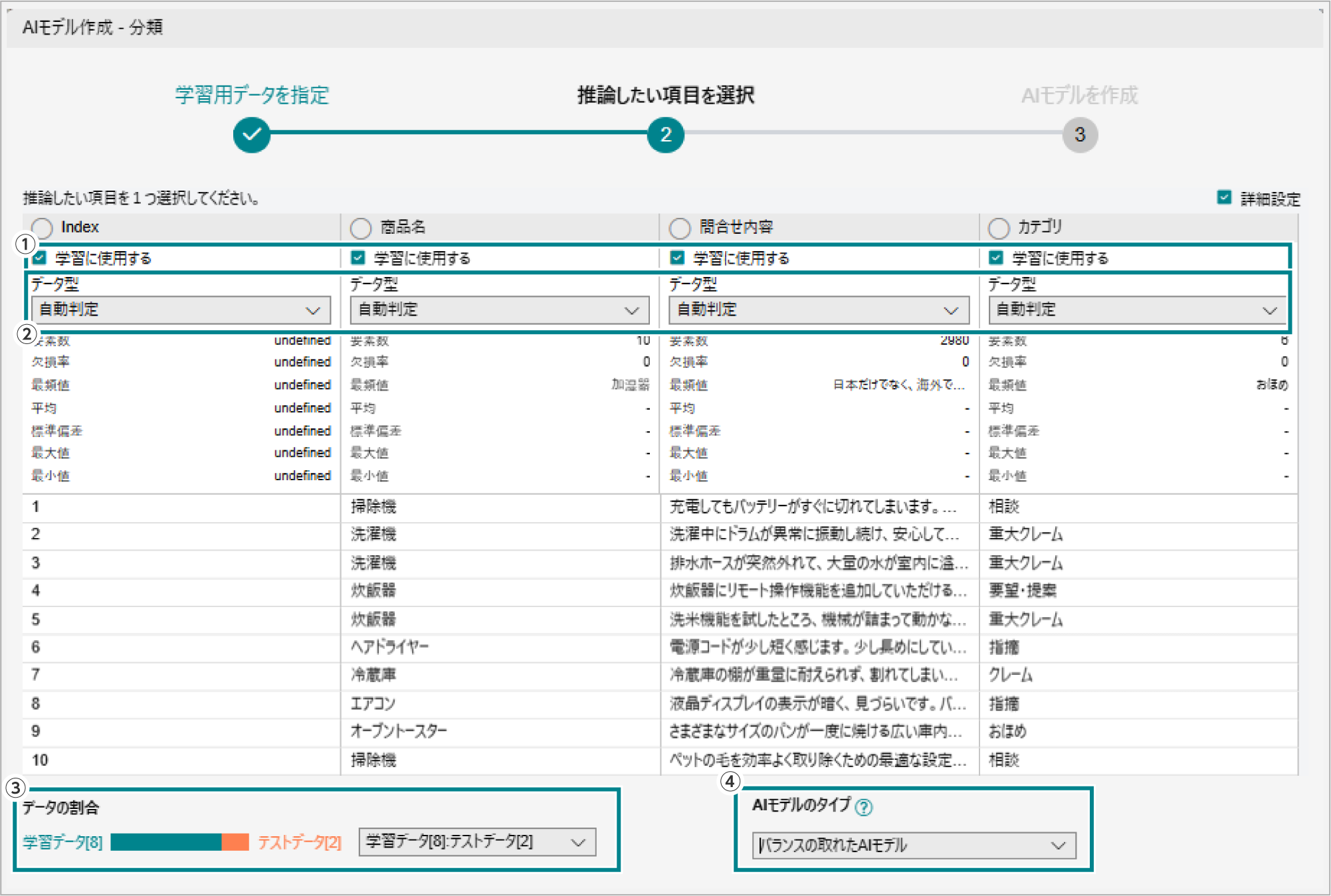
詳細設定の仕方
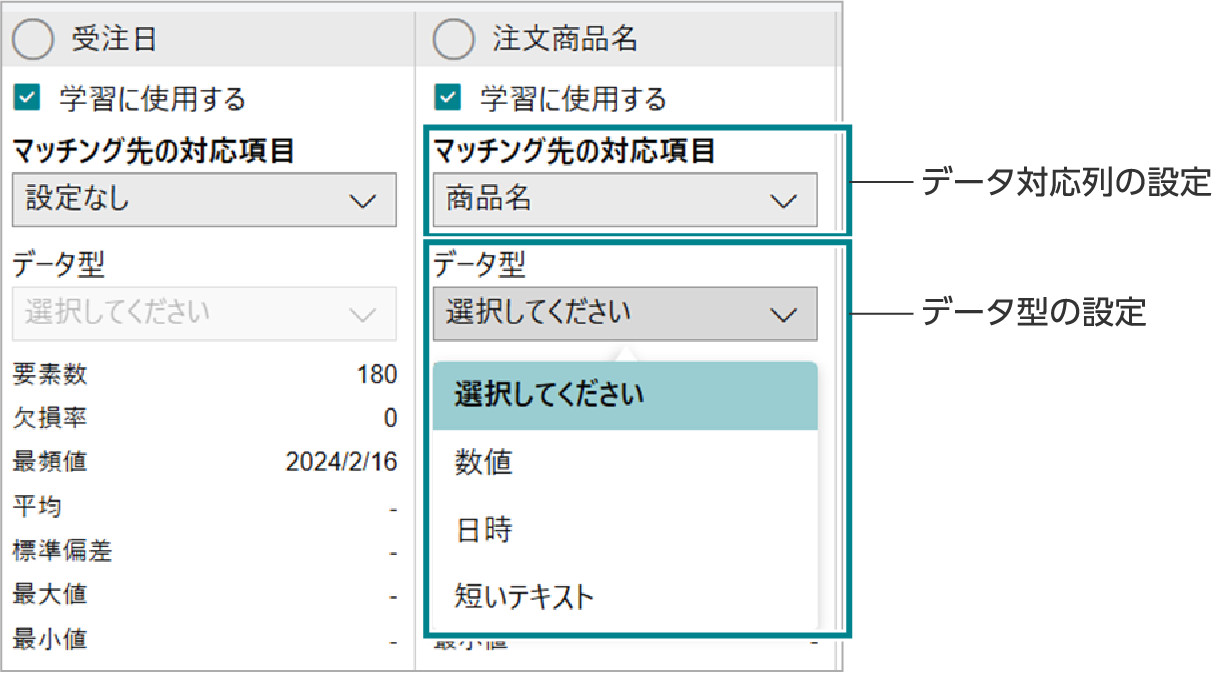
必要に応じて、学習の詳細設定ができます。データ型、2つのデータ間の対応項目(データマッチング、入金請求突合のみ)、AIモデルのタイプ、学習データとテストデータの割合の設定があります。
| データ型の指定 |
分類では、5種類の型を選択することができます。設定しない場合は自動で判定されます。 データマッチングと入金請求突合の場合には、2つのデータ間の対応項目を設定した場合、データ型も設定をする必要があります。3種類の型から選択してください。 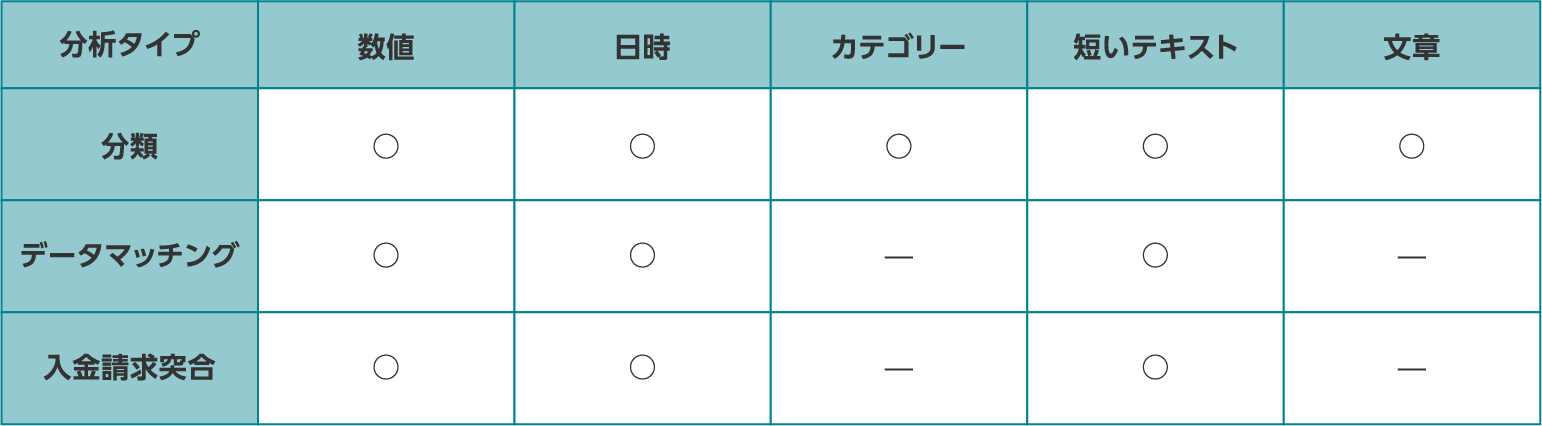 |
|---|---|
| データ型の種類 |
|
2つのデータ間の対応項目の指定
データマッチングと入金請求突合は、2つのデータを突合するため、それぞれのファイルに似た意味の説明変数が含まれていることが想定されます。それらの説明変数が対応することを、アナリティクス上で設定することが可能です。
【データマッチングの例】
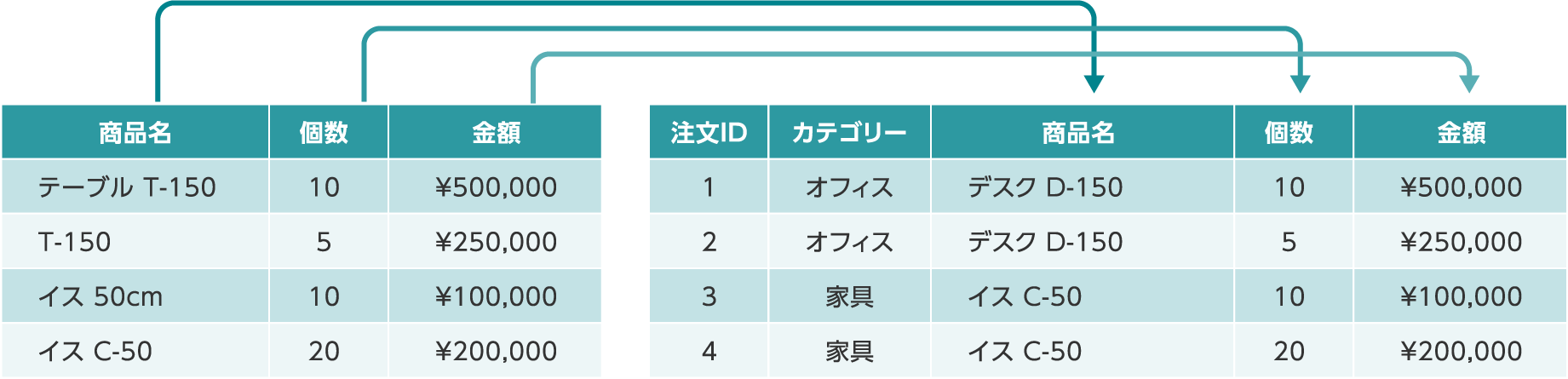
データ対応列を設定する場合は、データ型の設定も必要です。
AIモデルのタイプの選び方
AIモデルのタイプは「バランスの取れたAIモデル」「間違わないことを重視したAIモデル」「見逃しを抑えることを重視したAIモデル」の3種類です。
デフォルト設定では、バランスの取れたAIモデルが選択されています。
業務目的に応じて間違わないことを重視したAIモデル、見逃しを抑えることを重視したAIモデルへの変更を検討してください。
デフォルトのAIモデル
- バランスの取れたAIモデル
-
このAIモデルは、正確さと見逃しの少なさのバランスを重視しています。
全体的なパフォーマンスを評価するために、バランス評価(F値)を使用します。F値(F1 Score)を重視します

推論の正確さを重視する場合

- 間違わないことを重視したAIモデル
-
推論の正確さ(適合率)を高めることで、誤推論を減らします。
適合率を重視します。
事例
販促ターゲットの抽出
ユーザに無関係なアイテムをおすすめするとユーザー満足度が低下するため、誤り抑制を重視したAIモデルを選択します。
見逃しの少なさを重視する場合
- 見逃しを抑えることを
重視したAIモデル -
見逃しの少なさ(再現率)を高めることで、見逃しを最小限に抑えます。
再現率を重視します。

事例
顧客離反予測
顧客離反の兆候の見逃しを防ぐため、見逃しの少なさを重視したAIモデルを選択します。
データ割合の指定
アナリティクスに入力された学習用データは、学習データとテストデータに分割されます。
学習データは、AIモデルの学習に使用するデータです。
テストデータは、学習には使用せず、学習データを用いて作成したAIモデルの精度を測るために使用するデータです。
- デフォルトでは学習データ8:テストデータ2の割合で設定されています。
- 学習用データのデータ量などに応じてデータ割合の変更を検討してください。
例:学習用データのデータ量が多く、学習に十分なデータ量が確保できている場合、未知のデータへの精度確認を重視し、7:3、6:4などテストデータの割合を増やす。
- 参考
- データの割合を変更する

需要予測
学習してAIモデルを作成する
アナリティクスに学習用データを入力し、分析タイプに応じて学習に必要な設定をします。
- 推論する項目(目的変数)を選択します。
- 日付を表す項目に、利用したい時系列データが選択されているか確認します。異なる場合は、正しい項目を選択します。
- 推論する単位と推論する期間を選択します。
- 必要に応じて、系列や気象情報の考慮、実績値の補完方法、学習に使用する項目の設定を行います。
- 正しい日付の項目が表示されない場合は、学習用データを見直す必要があります。形式が異なる値が複数存在する場合は、日付を表す項目の候補として表示されません。
各種設定の仕方
推論する項目、日付を表す項目、推論する単位と推論する期間を設定します。必要に応じて、系列を表す項目、気象情報、実績値の補完方法、学習に使用する項目を設定することができます。
推論する単位と推論する期間
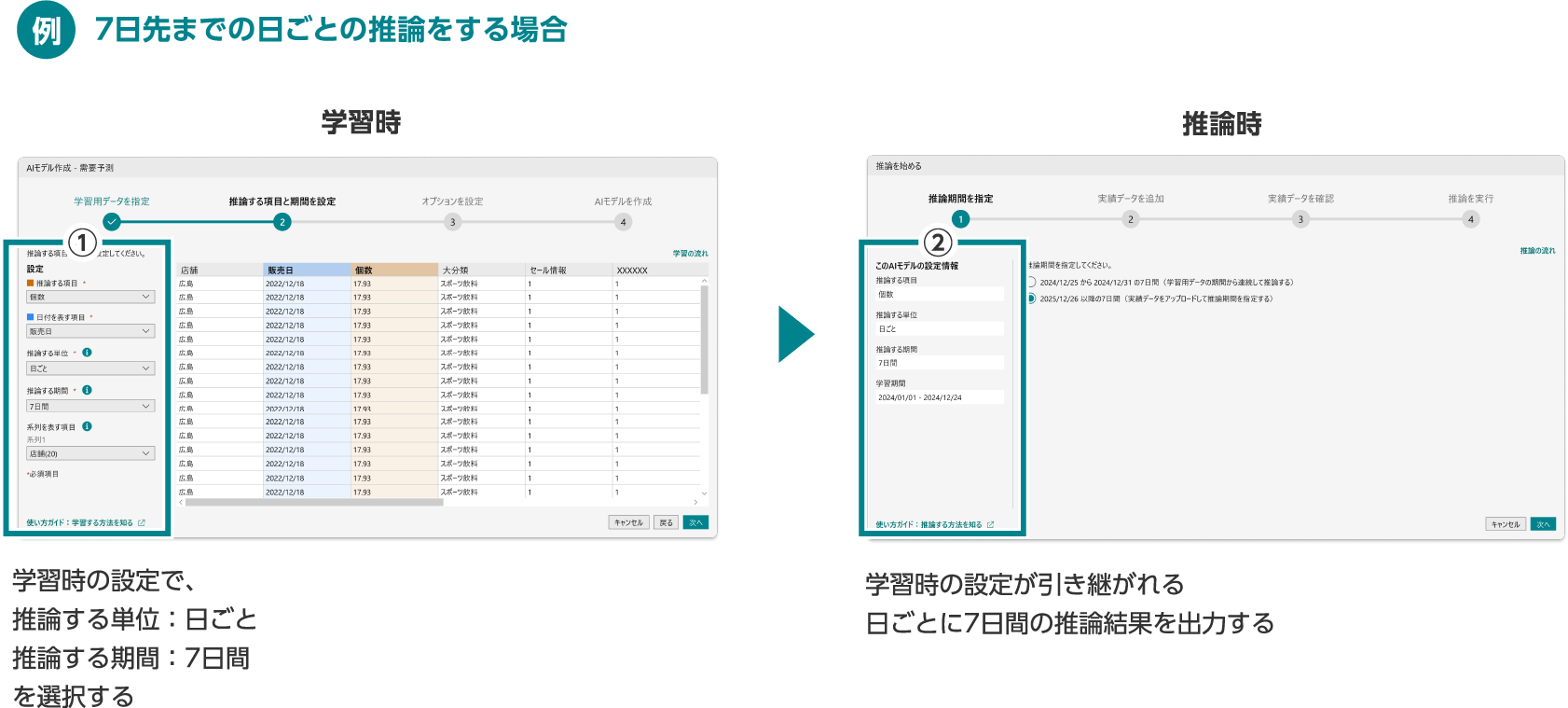
需要予測では、推論結果を得たい分析の単位と期間を、学習時に「推論する単位」「推論する期間」として設定します。学習時の設定は、推論時にも引き継がれます。
例:7日先までの日ごとの推論をする場合には、学習時に①を設定します。
推論時には、学習時の設定が引き継がれ、日ごとの7日間の推論が行われます。
※②の設定情報でも確認することができます。

推論する単位
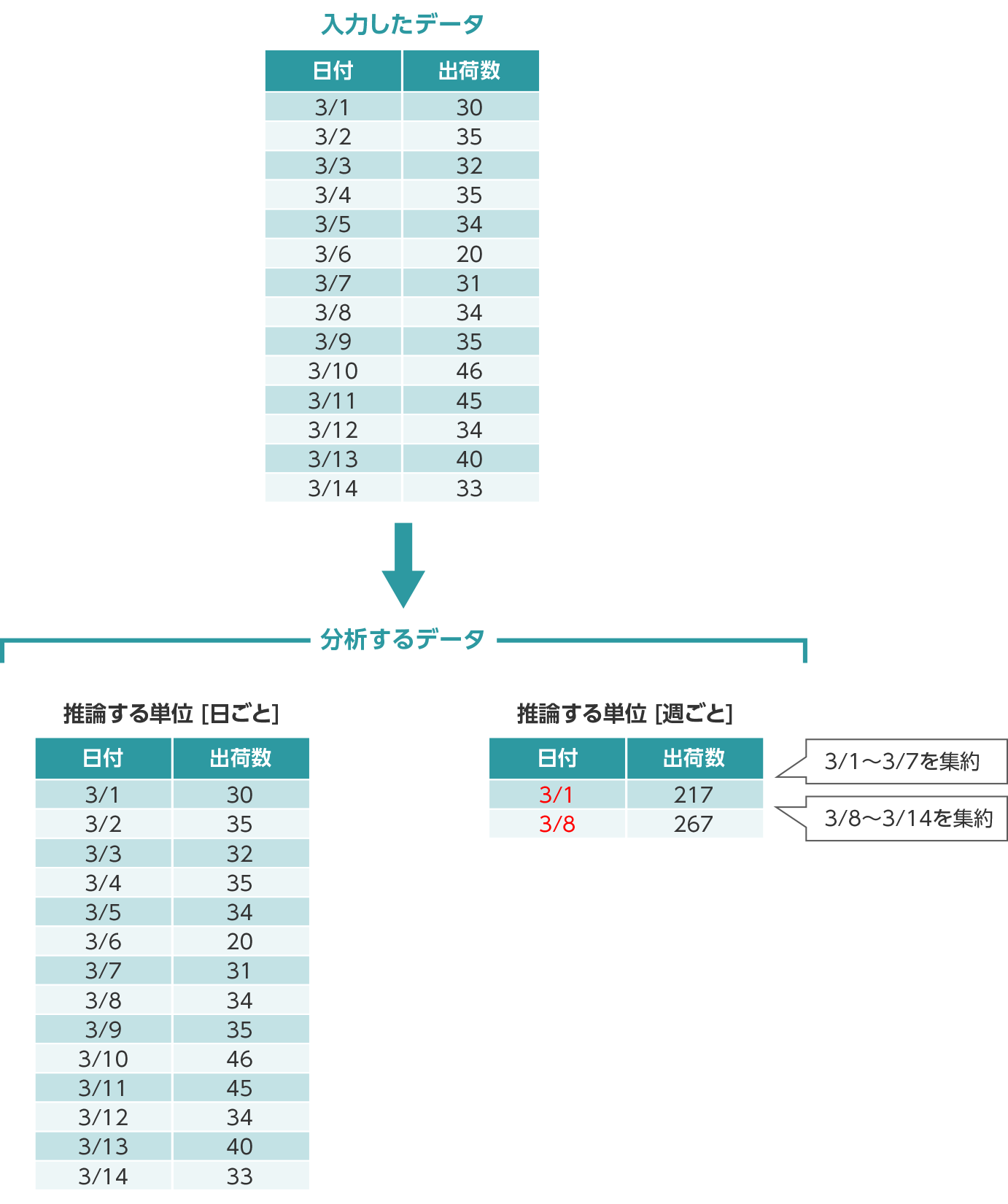
選択できる単位は、「日ごと」「週ごと」「月ごと」「年ごと」の4つです。
入力したデータの「日付を表す項目」に入力された日付の間隔をシステムが判断し、自動で初期値を設定します。例えば、日次のデータを入力すると、初期値として「日ごと」が選択されます。
入力したデータの日付の間隔よりも長い間隔で分析したい場合は、推論する単位を変更することで、自動的に設定された日付の間隔単位で、入力したデータの「推論する項目」の値を集計します。
例えば、日次のデータを入力したが週次単位で分析したい場合は、「週ごと」に変更します。
推論する期間
選択できる期間は、推論する単位によって異なります。
推論する期間は、設定可能な値の範囲内で指定してください。

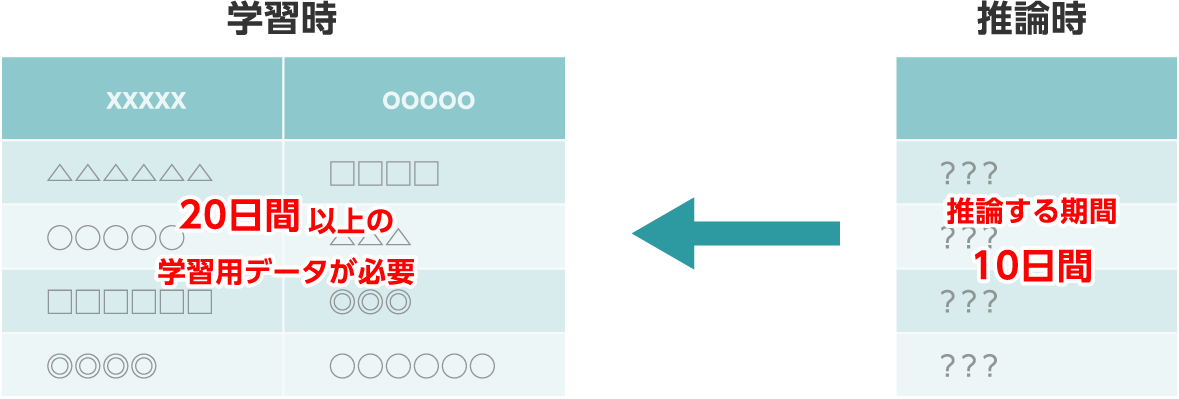
- 推論する期間には学習期間の長さに応じて制限があります。推論する期間の倍以上の学習用データを用意してください。
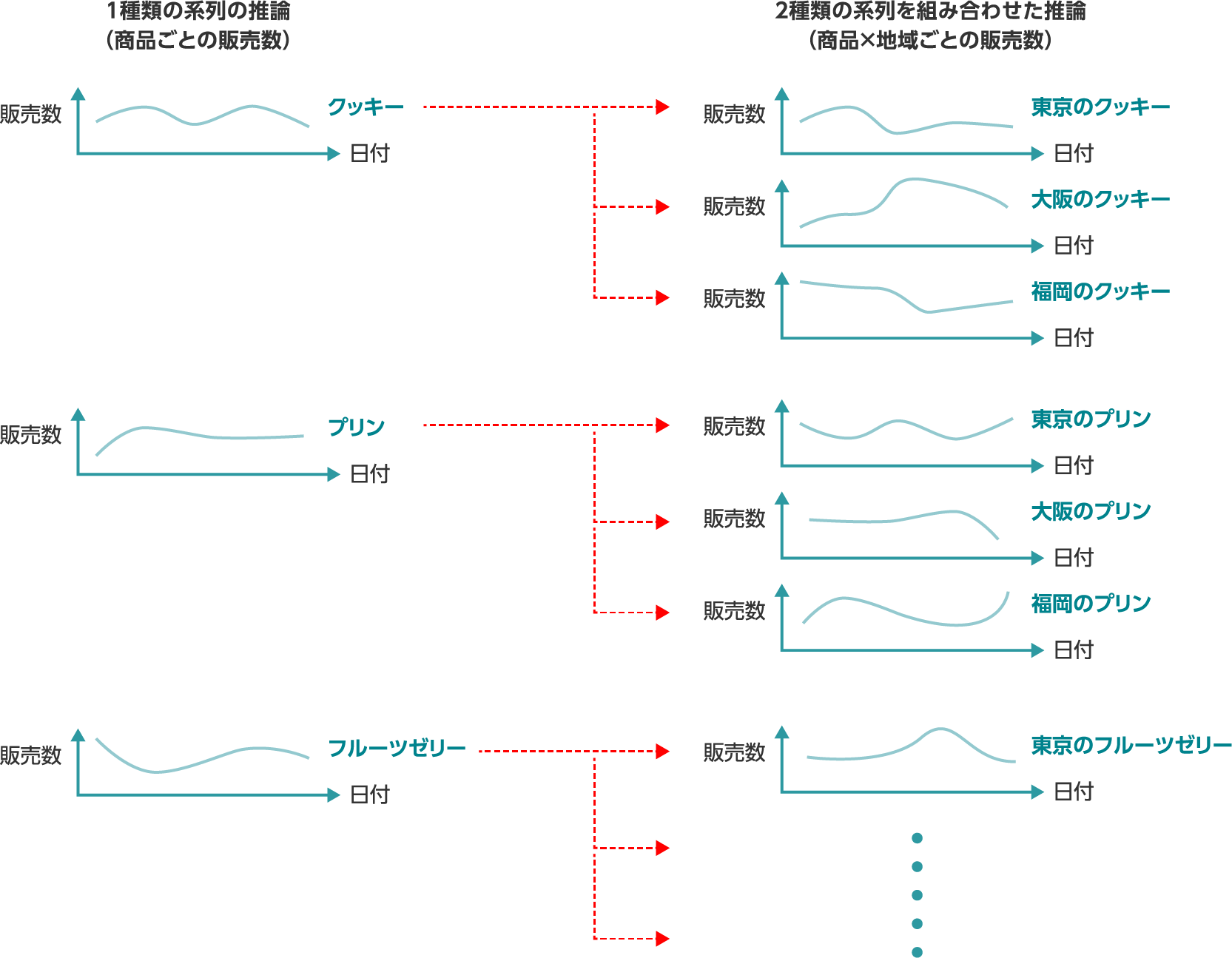
系列を表す項目
同じ項目内に複数の分析対象がある場合に系列を指定すると、指定された系列別に推論します。
例:製品A、製品B、製品Cが値として含まれる「製品名」を系列に指定すると、それぞれの製品の販売数を推論します。
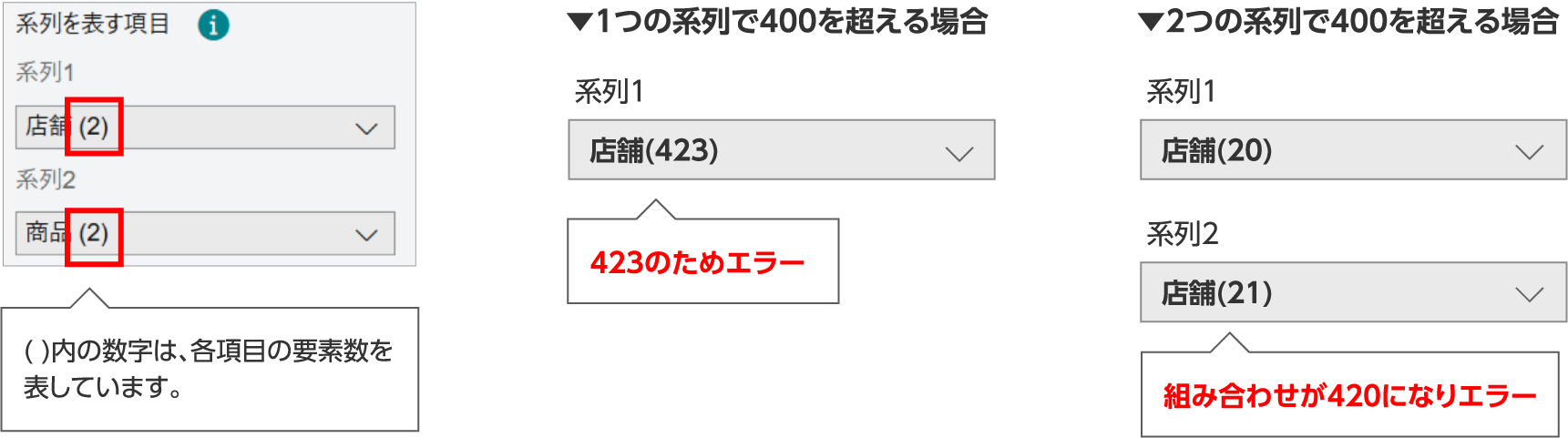
学習できる系列数は最大で400です。系列1のみ選択する場合は、項目の要素数が400以下のものを選択してください。系列1と系列2とも選択する場合は、各項目の要素数を掛け合わせた数が400以下になるように選択してください。
エラーの場合
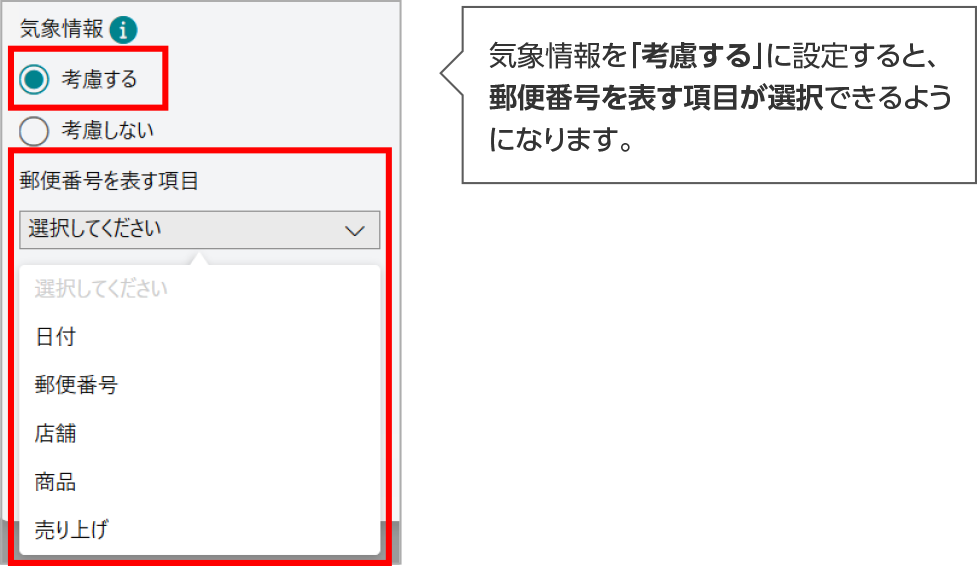
気象情報の考慮
「推論する単位」が「日ごと」の場合に、気象情報を分析に加えることができます。
学習時には、過去の天気、最低気温、最高気温の気象情報を自動で付与して学習します。気象情報を考慮したAIモデルを利用して推論する場合は、推論実行時から10日先までの天気予報を考慮します。
気象情報を考慮する場合は、郵便番号から地点の情報を取得します。「郵便番号を表す項目」がデータに含まれている必要があります。
実績値の補完方法
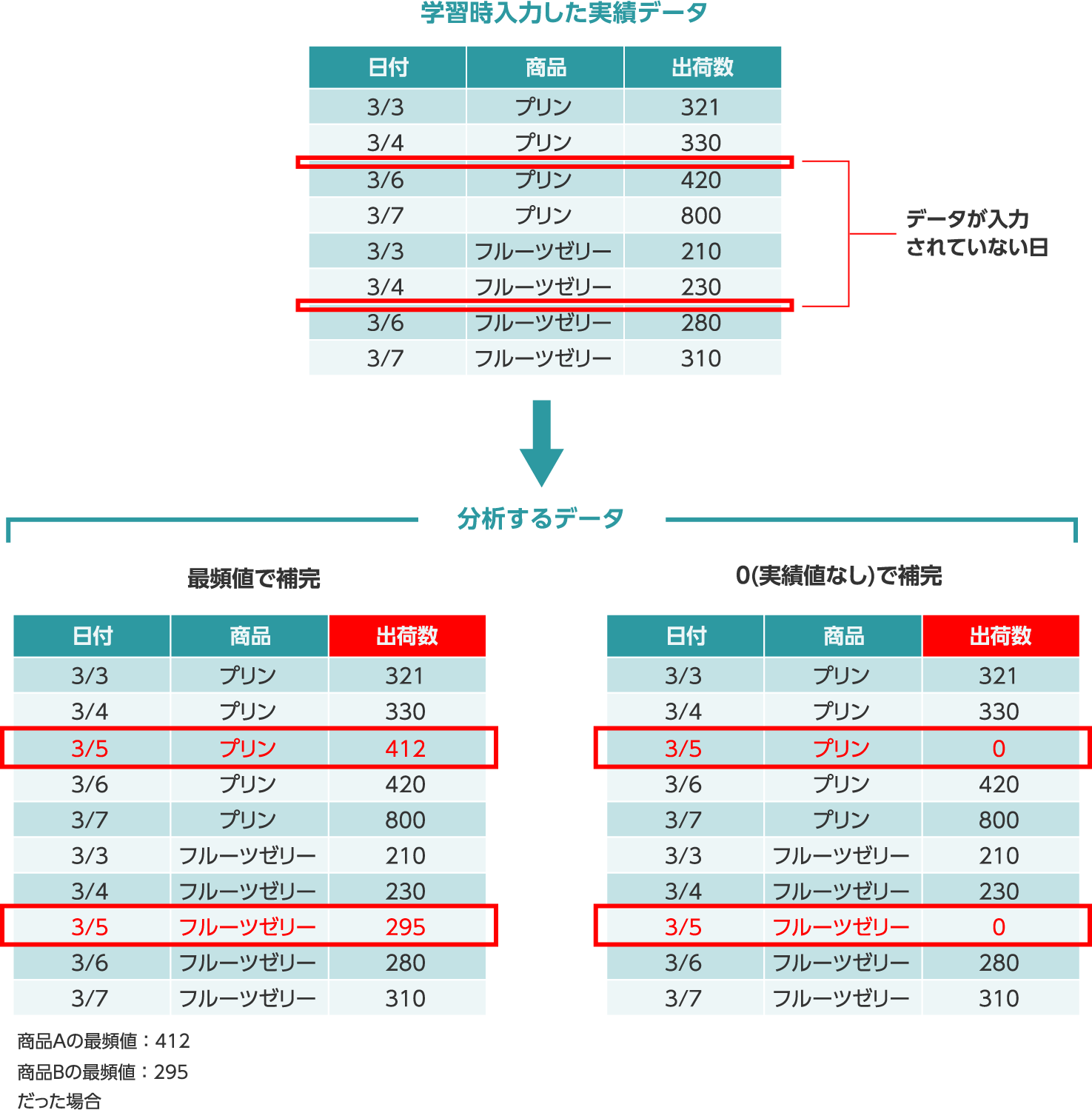
「日付を表す項目」の値は連続していることを前提としています。しかし、学習/推論時のデータにおいて休業日などで日付が連続しない場合には、連続するようにデータを自動で補います。初期設定では、連続していない日付の「推論する項目」の値を[最頻値]で補いますが、実績値がないことが明確な場合には[0(実績値なし)]で補う設定に変更します。系列が設定されている場合は、系列ごとに欠損している日付と他の項目の実績値を補います。学習時の設定は、推論時にも引き継がれます。
学習に使用する項目の設定方法
割引率や広告の掲載情報などのお客様固有の要因を考慮して需要予測を行いたい場合は、学習に使用する項目として設定することができます。
「学習に使用する」に設定した項目は、数値型とカテゴリー型の2種類からデータ型を選択します。
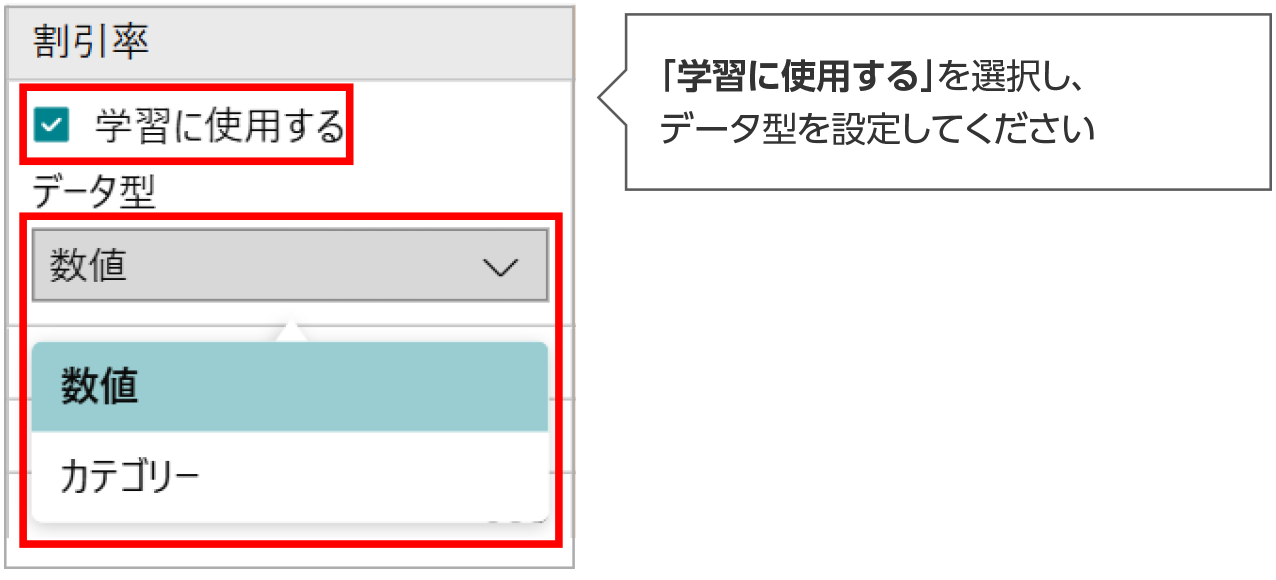
- 「すべての項目を学習に使用する」を選択すると、すべての項目の「学習に使用する」が選択できます。
- 数値型では、数値の増減による特徴を学習します。
- カテゴリー型では、値ごとの特徴を学習します。
- 推論する単位を初期設定から変更した場合は、学習に使用する項目の設定ができません。
- 値がすべて数値の列のみ数値型として指定できます。
- カテゴリー型は要素数が100以下の場合のみ指定できます。
学習に使用する項目の設定例
学習に使用する項目に設定すると、その項目が説明変数としてAIモデルの学習に使われます。
説明変数とは、売上などの目的変数の変動を説明する要素のことです。
例えば、売上を予測する場合は、割引率やセールの種類などが説明変数になります。
これらを適切に設定すると、売上の変動をより正確にとらえ、予測の精度を高めることができます。

売上の予測以外でも、生産量や不動産価格など予測の目的に応じて適切な説明変数を設定することで、変動の特徴を捉えやすくなります。
予測の対象や用途に合わせて、説明変数の種類や内容を調整することで、より効果的に活用できます。
- 名前やラベルを表す数字をデータに使う場合は、データ型を「カテゴリー」に設定することを推奨します。
- 予測に使用する説明変数で似た情報が重なると、AIモデルが違いをうまく区別できなくなることがあります。例えば、売上予測では「店舗の広さ」と「従業員数」が広い店舗ほど従業員が多い傾向があるため、似た内容のデータとなります。このような場合は、どちらか一方だけを使うことを推奨します。
分類・データマッチング
の学習結果を確認する
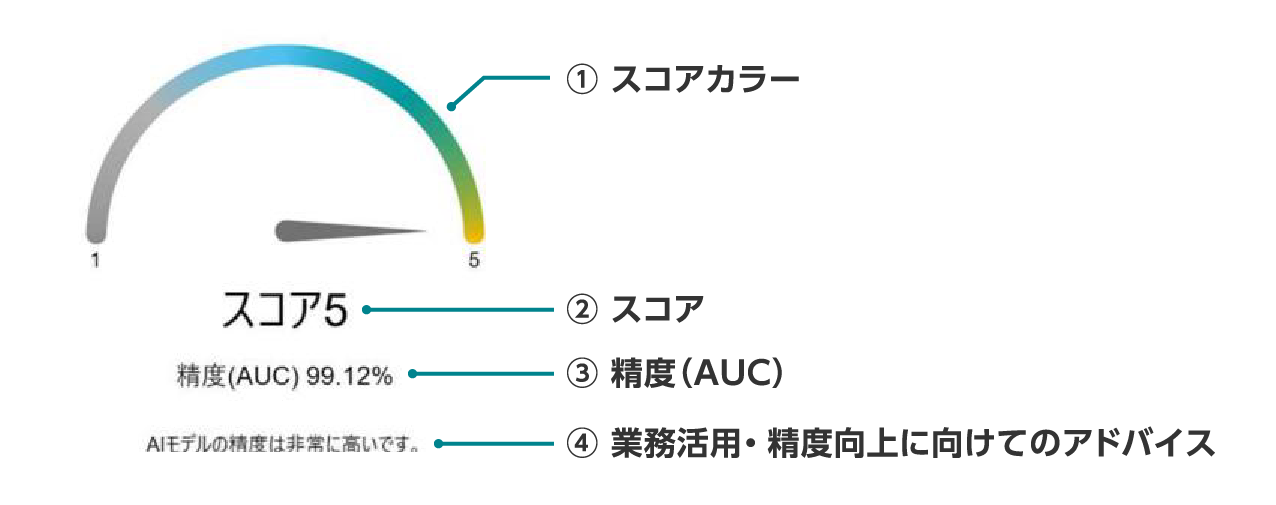
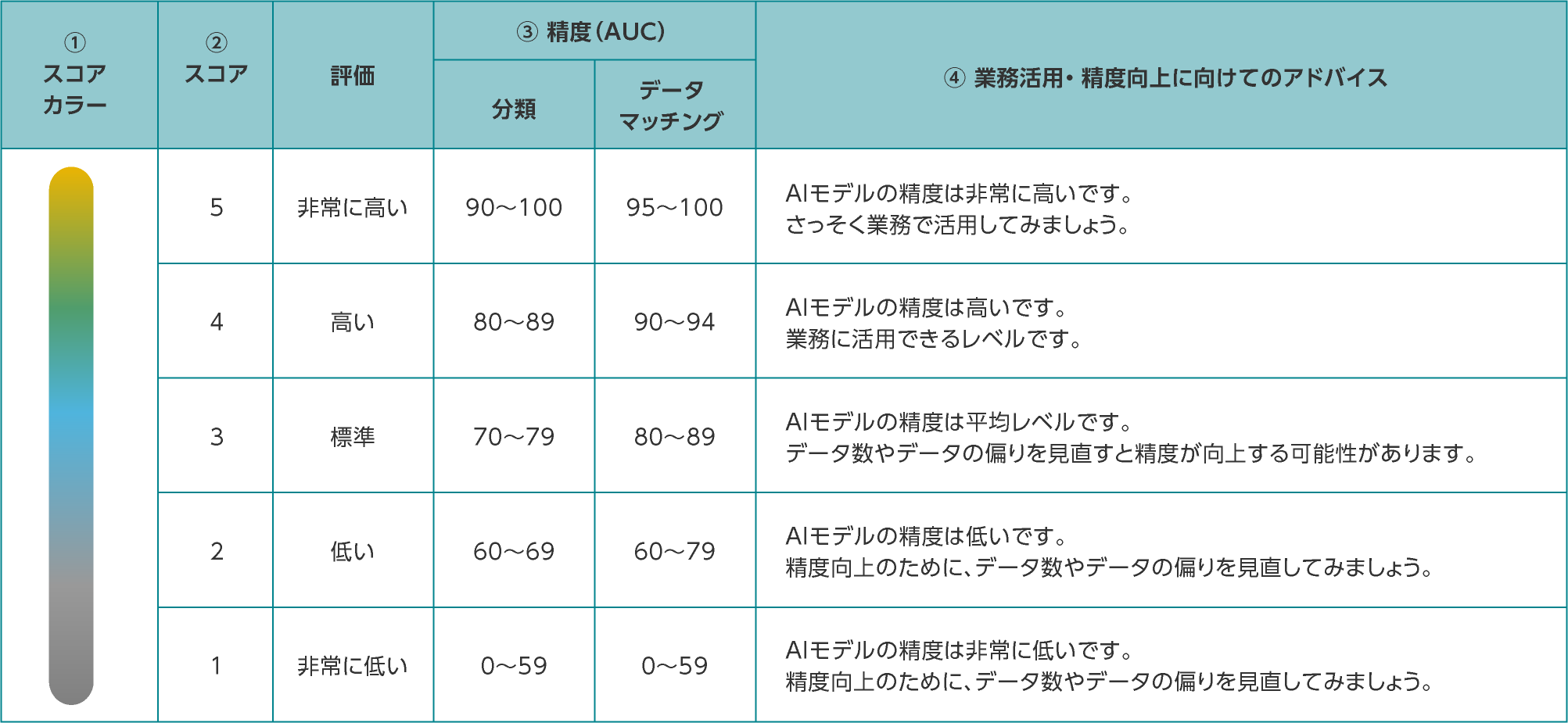
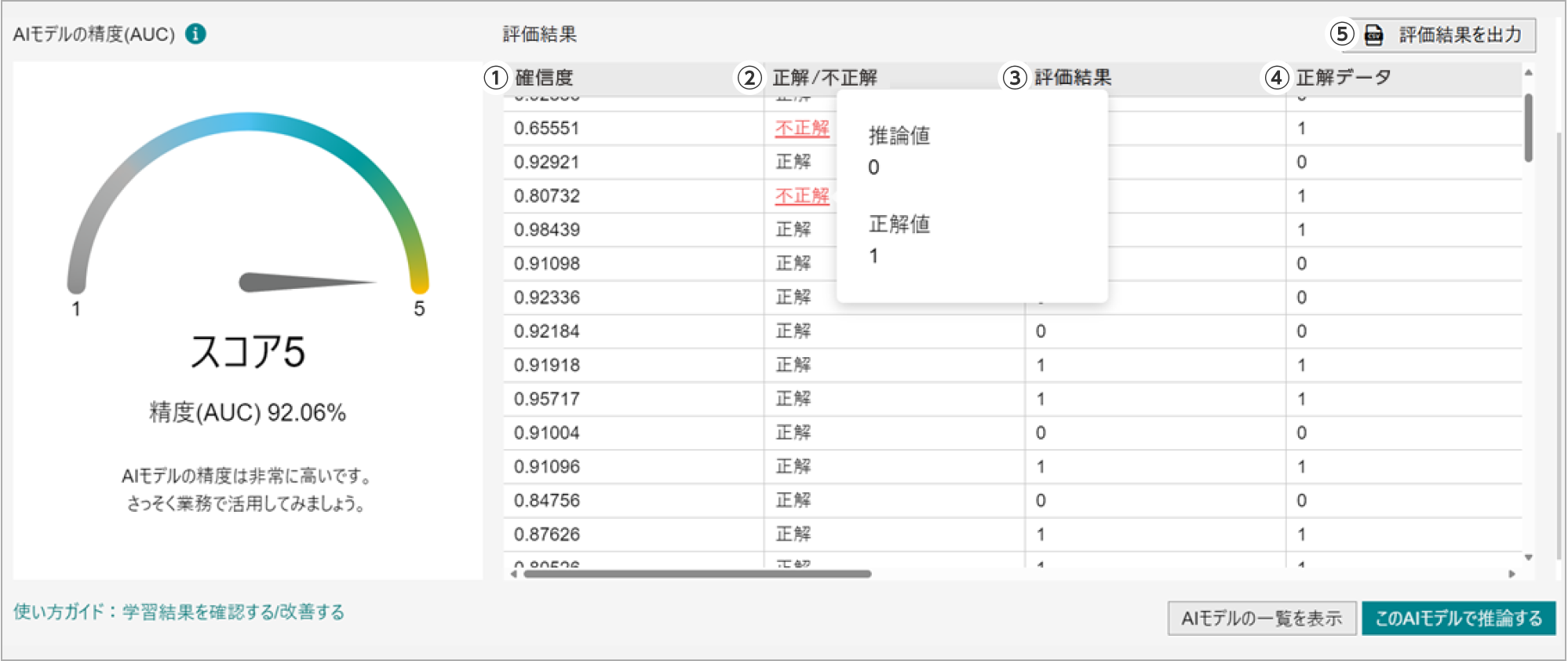
分類・データマッチングの学習結果は、5段階スコア、テストデータの評価結果、主要スコアで確認します。
AIモデルの精度
AIモデルの性能を示す参考値です。業務に活用できるかどうかの判断や、さらなる性能向上を目指すかどうかの目安にします。
- 精度を向上させたい時:学習結果(AIモデル)を改善する
テストデータの評価結果
テストデータの評価結果には、次の項目があります。
- ①確信度:AIモデルがどの程度自信を持って推論したかの割合
- ②正解/不正解:学習用データの目的変数に指定した値を推論できたか否か
- ③評価結果:AIモデルが推論した値
- ④正解データ:学習データに含まれる目的変数
- ⑤評価結果を出力:テストデータの評価結果をCSV出力することもできます。
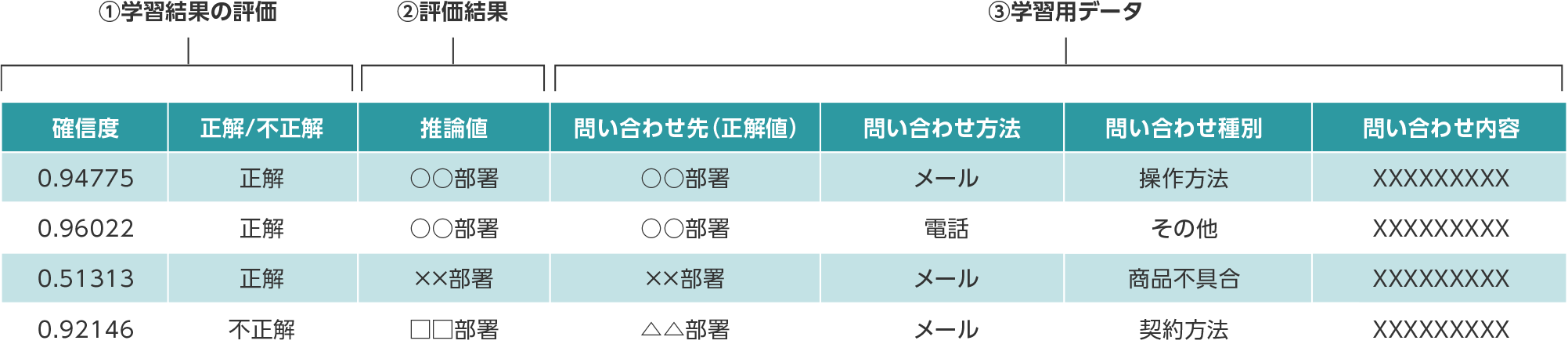
評価結果のCSVファイルの見方
分類
- ①学習結果の評価(先頭2項目)
確信度:AIモデルがどの程度自信を持って推論したかの割合
正解/不正解:学習用データの推論したい項目(目的変数)に指定した値と指定したデータを推論できたか否か - ②評価結果:AIモデルが推論したデータ
- ③学習用データ(4項目目以降)
データマッチング
マッチング元データに対して、推論したマッチング先データと正解のマッチング先データが組み合わせで出力されます。
- ①学習結果(先頭2項目)
確信度:AIモデルがどの程度自信を持って推論したかの割合
正解/不正解:学習用データで共通キー項目(推論したい項目(目的変数)に指定した値)と指定したデータを推論できたか否か - ②評価結果:AIモデルが推論したデータ
- ③マッチング元データ:学習用データ
- ④マッチング先データ:学習用データ
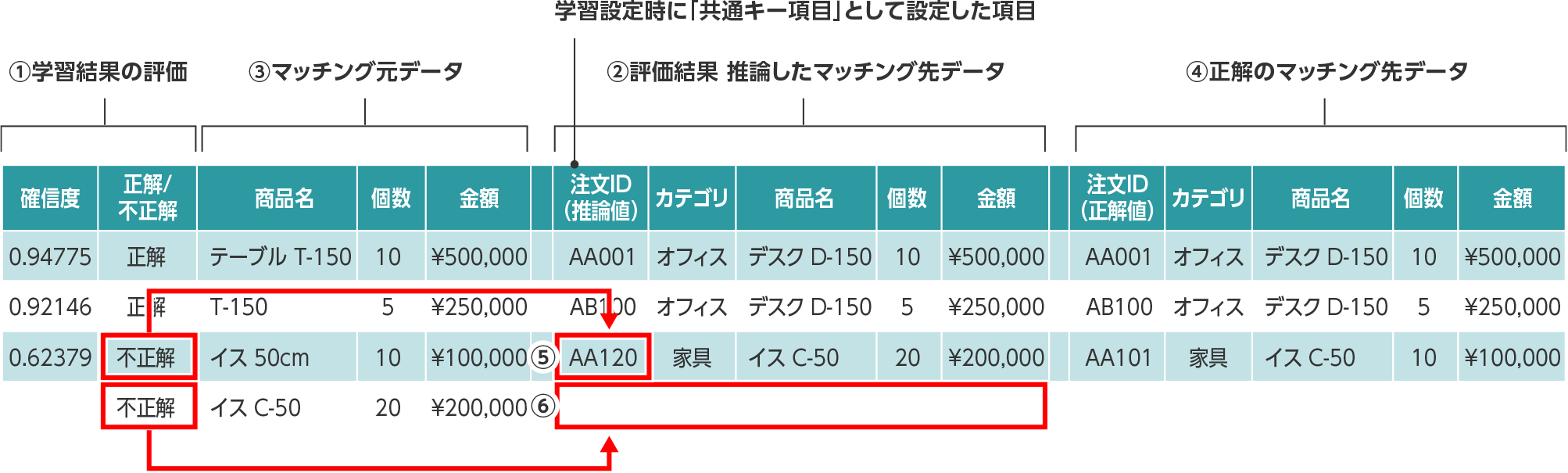
- ⑤評価結果が正解と異なるため不正解
- ⑥マッチング先を推論できていないため不正解
分類・データマッチングの学習結果を詳細に確認する
分類・データマッチングの学習の詳細結果は、主要スコア、混同行列、ROC曲線、PR曲線、特徴量重要度で確認します。
主要スコア
主要スコアは、選択したAIモデルのタイプと関連付けて見ていきます。
デフォルトのAIモデルの時はF値、間違わないことを重視したAIモデルの時は適合率、見逃しを抑えることを重視したAIモデルの時は再現率を重視します。
- 正解率
- 正確さ(Accuracy)を表します。すべての予測のうち、正しく予測された割合を指します。
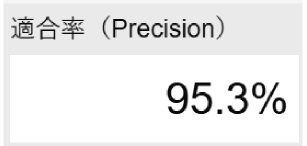
- 適合率
- 予測の正確さ(Precision)を表します。実際に正解であるケースのうち、正しく予測された割合を指します。
- 再現率
- 見逃しの少なさ(Recall)を表します。正しく予測されたケースのうち、実際に正解である割合を指します。
- F値
- バランス評価(F1 Score)を表します。予測の正確さと見逃しの少なさをバランスよく評価した値を指します。
AIモデルのタイプはあらかじめ選ぶこともできます。
- AIモデルのタイプを選ぶ際の参考
- AIモデルのタイプの選び方
混同行列を用いて、正解率、適合率、再現率、F値について説明します。
混同行列(Confusion Matrix)
- 参考
- 混同行列

正解率

正解率・正確さ (Accuracy)
全体のデータの中で正しく分類できた真陽性(TP)と真陰性(TN)がどれだけあるかという指標。
高いほど性能が良い。

再現率・適合率・F値

再現率・敏感度 (Recall, True Positive Rate)
取りこぼしなく陽性(Positive)なデータを正しく陽性と推測できているかどうか。
この値が高いほど性能が良く、間違った陽性の判断が少ないということ。
別の⾔い方をすれば、本来陽性と推測すべき全データの内、どれほど回収できたかという指標。

適合率・精度 (Precision)
陽性(Positive)と予測したデータの中で実際に陽性だったデータの割合。
この値が高いほど性能が良く、間違った推論が少ないということを意味する。

F値(F1 Score)
F値は適合率と再現率の調和平均。
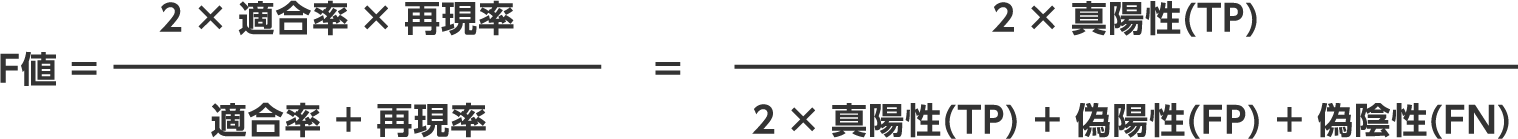
混同行列
混同行列は、予測結果とその実際の正解をまとめた表のことです。AIモデルの性能を詳しく知りたいときに使います。
表の中の数字はサンプル数を表しており、実際のサンプル数のうち正しく予測できたサンプル数や、予測したサンプル数のうち、予測が外れてしまったサンプル数などがわかります。

【例】受信したメールからスパムメールを検出する場合

正解率:1,000 件のメールのうち正しく推論できたメールが 800 件のため、 800/1,000 = 0.80
再現率:スパムメール400件のうち350件を正しく検出したため、350/(350+50)=0.875
適合率:スパムメールと推論した500件のうち350件を正しく検出したため、350/(350+150)=0.7
ROC曲線、PR曲線
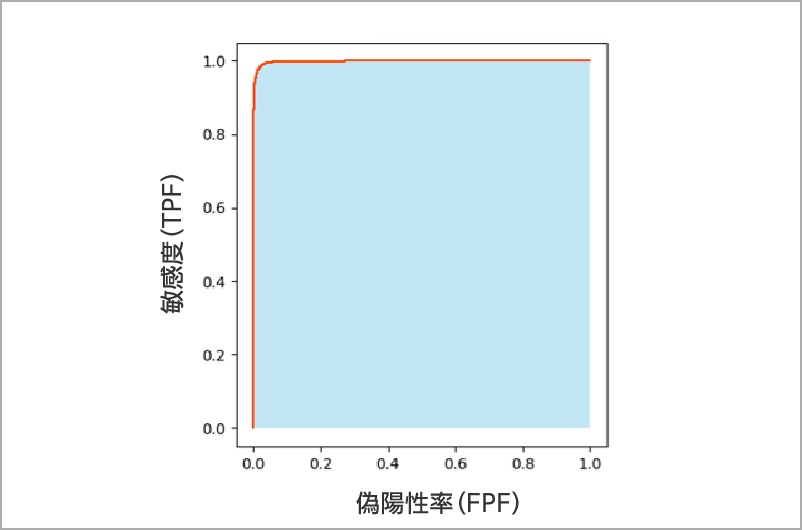
ROC曲線
ROC曲線は「推論したい項目」の各要素の偽陽性率(FPF)と敏感度(TPF)の関係をそれぞれプロットした曲線であり、AIモデルの性能を可視化したいときに確認します。
この曲線の下の面積が分類精度AUCを表すため、この面積は1に近づくほど精度がよいと評価できます。
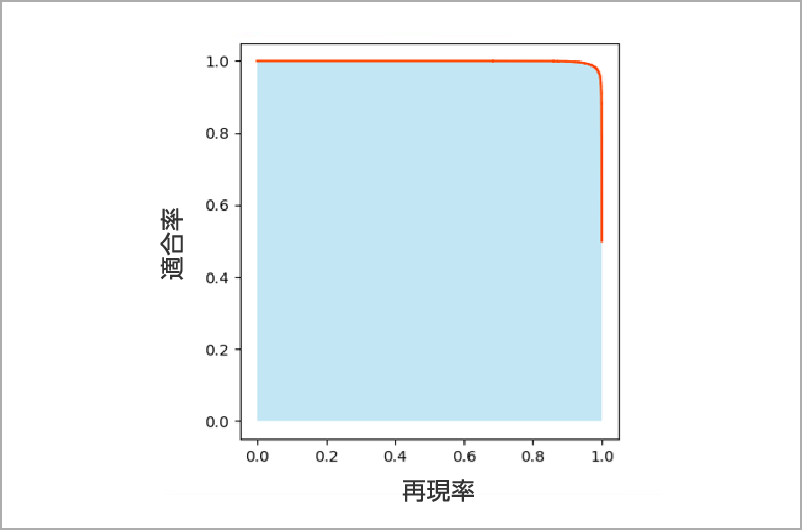
PR曲線
PR曲線は「推論したい項目」の各要素の再現率と適合率の関係をそれぞれプロットした曲線であり、AIモデルの性能を可視化したいときに確認します。
この曲線の下の面積が分類精度APを表すため、面積が1に近づくほど精度がよいと評価できます。
敏感度・偽陽性率

敏感度(TPF)
正解が陽性(Positive)のデータの中で正しく予測できたデータの割合

偽陽性率(FPF)
正解が陰性(Negative)のデータの中で誤って予測したデータの割合

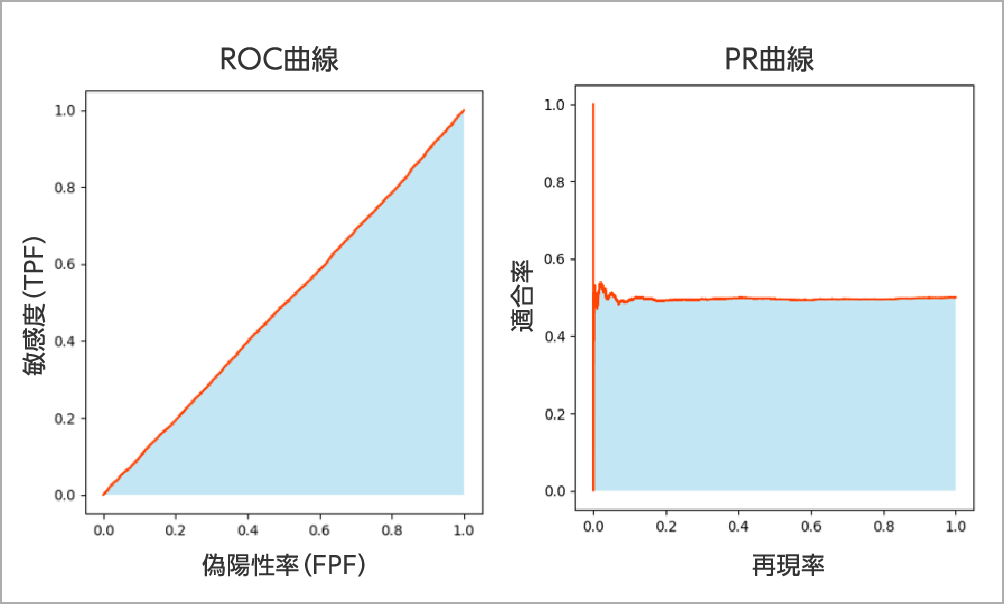
うまく学習できていない例
【例】有効な説明変数がなく、ランダムに推論している
対策:学習用データの説明変数を増やす。
独自に特徴量を作成し、学習用データに説明変数として加える。
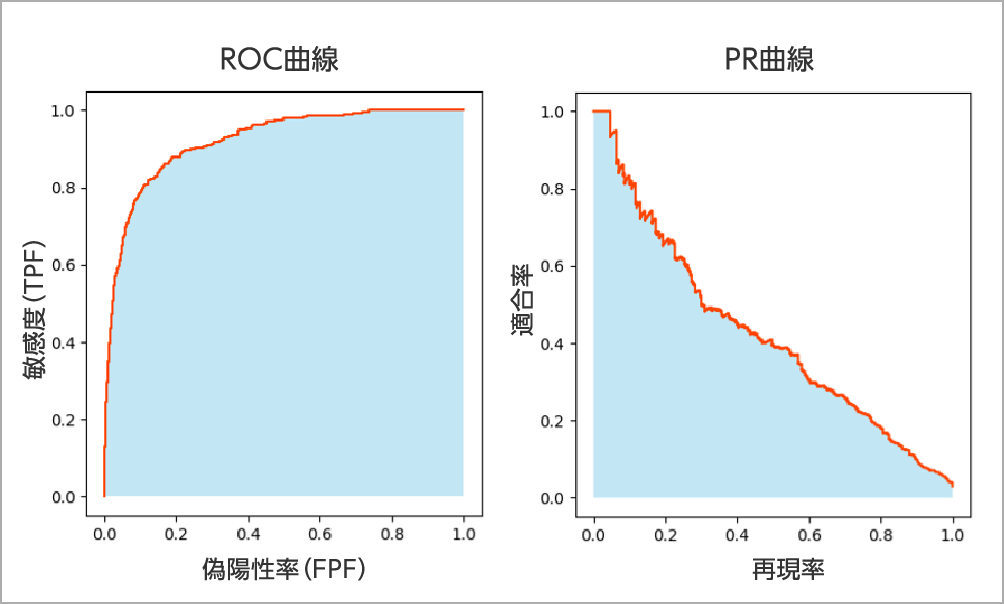
【例】目的変数の分布が偏っている
対策:学習用データの目的変数の分布を見直す。
例:陰性(Negative)データが少ない場合
- 学習結果(AIモデル)を改善する-データ取得時期の偏りがないか?
- 学習用データから目的変数が陽性(Positive)のデータを減らす
特徴量重要度
特徴量重要度は、学習用データの説明変数などの特徴量がどの程度重要かを表した数値です。
推論に必要な特徴量であるほど値が大きく、重要度に応じて降順で表示します。
分類の特徴量重要度
説明変数、もしくは説明変数に含まれる特定の値がどのくらい重要と判断して結果を出したか、を確認できます。
特徴量生成方法について:データ型によって生成される特徴量は異なります。生成された特徴量が重要だった場合、値が表示されます。
マーケティングにおいてDMを優先的に配信する顧客を選定する際に、購入見込みの高い顧客を分類する下図の例では、「累計購入金額」や入会日から算出した「在籍期間」の項目が重要だと分析されています。この結果が経験と合っているか、もしくは新たな観点である場合は、学習結果を受け入れられるか判断します。

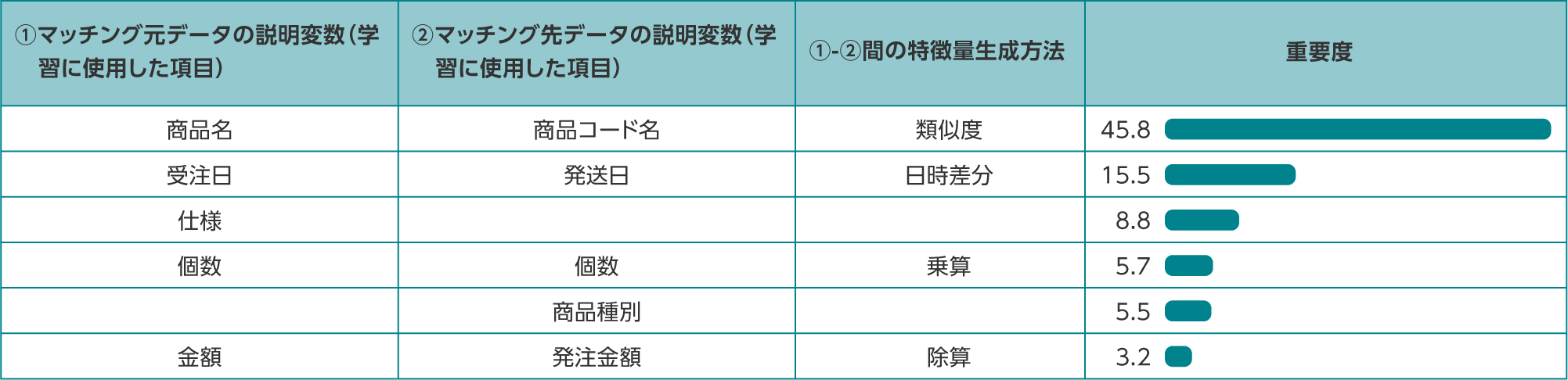
データマッチングの特徴量重要度
①マッチング元データ、②マッチング先データそれぞれの説明変数、もしくは①マッチング元データと②マッチング先データを比較して生成した特徴量がどのくらい重要と判断して結果を出したか、を確認できます。
特徴量生成方法について:データ型によって生成される特徴量は異なります。生成された特徴量が重要だった場合、値が表示されます。
注文リストと受注システムのデータをマッチングする例では、 「商品名」と「商品コード」の文字列の類似度が一番重要であるという結果になります。
入金請求突合の
学習結果を確認する
入金請求突合の結果は、突合の精度とテストデータの評価結果とで構成されています。
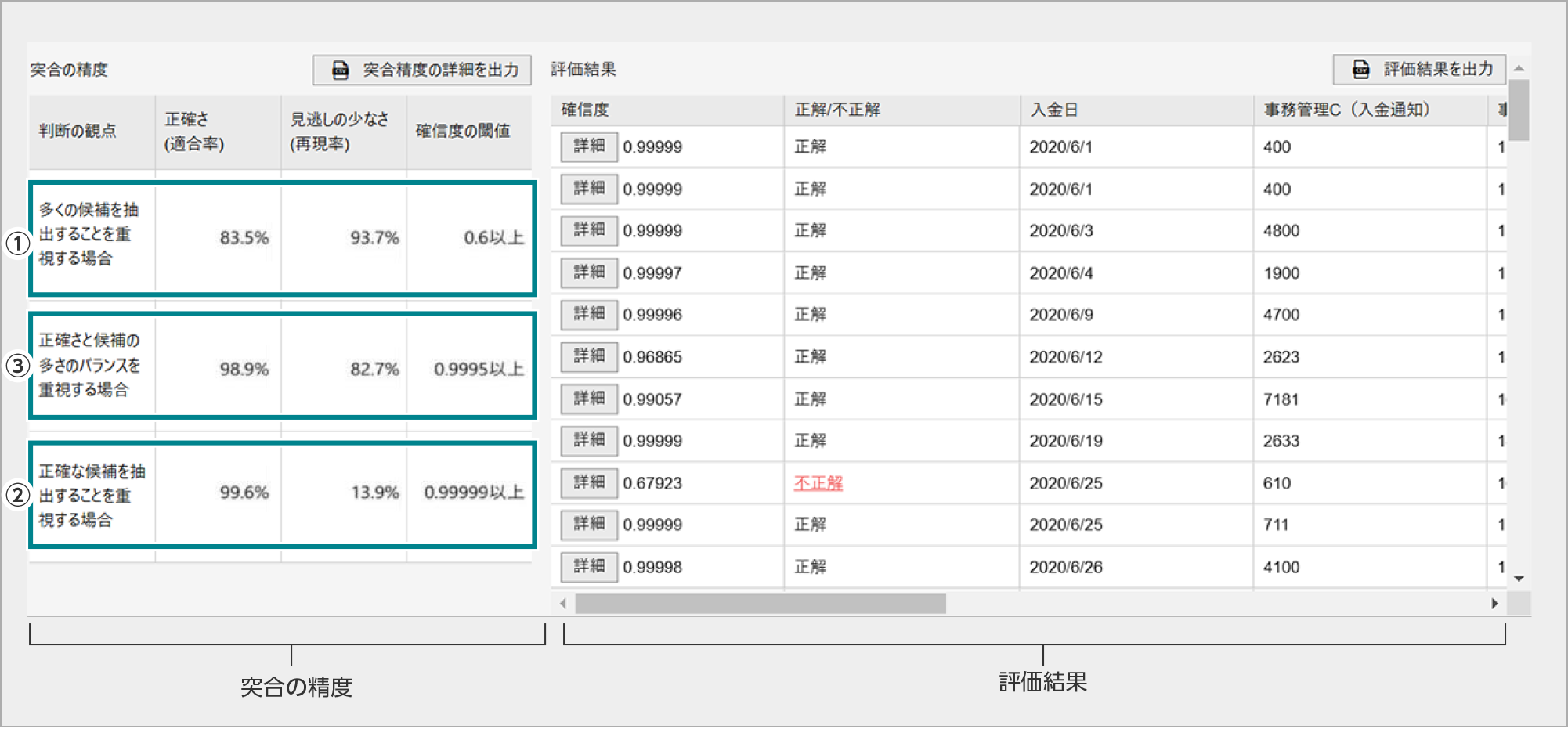
突合の精度
突合の精度(左側表)からAIモデルを評価および運用するイメージを例で説明します。
- ①はAIにより多くの正解を求めるようなケースです。マッチングの確信度は低くなりますが、見逃しがないように、より多くのマッチング候補を抽出します。AIの結果を参考に、人が確認して判断するような運用を想定したケースです。
- ②はAIにより正しい結果を求めるようなケースです。抽出するマッチング候補は少なくなりますが、正確な結果を得るために確信度の高いマッチング候補のみを抽出します。AIの結果をある程度信用して、他の見逃されたマッチングを人が補足して実施するような運用を想定したケースです。
- ③はその中間です。
「ゴールを設定する/業務課題を設定する」で設定したゴールと見比べて、学習結果が許容されるかを判断します。
突合の精度
突合の精度では、適合率(Precision)と再現率(Recall)を用いて精度の表を表示しています。
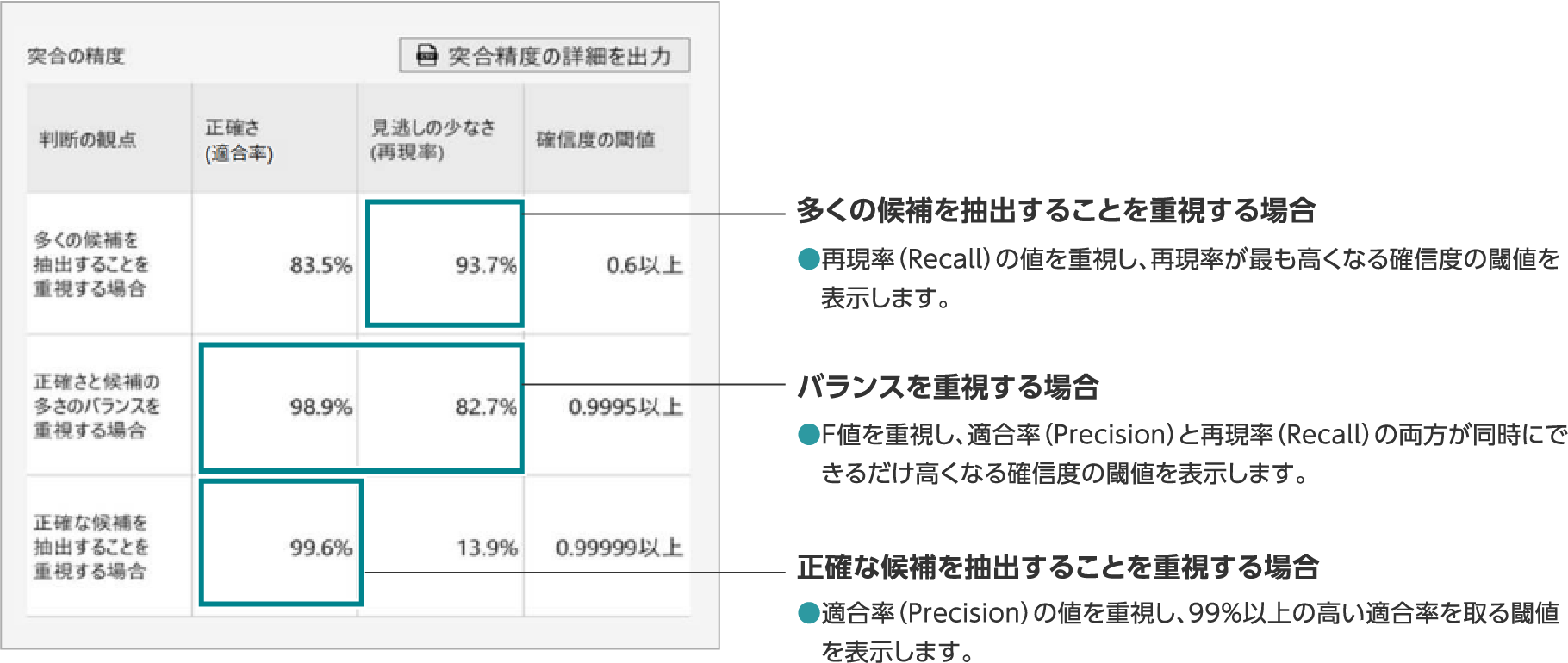
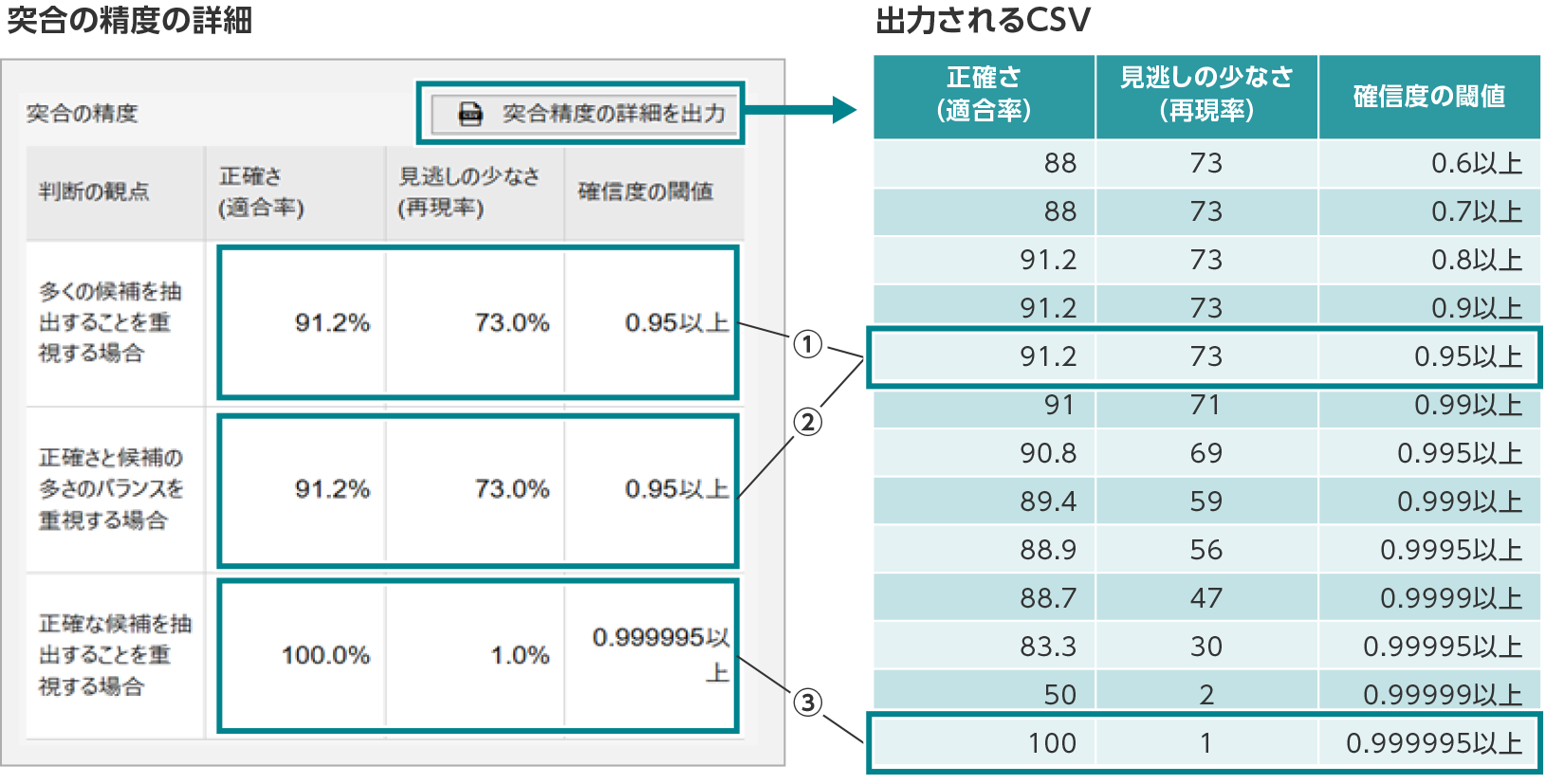
突合の精度の選ばれ方
-
①多くの候補を抽出することを重視する場合
- 再現率(Recall)が全く同じ場合は、適合率(Precision)が最も高い閾値を選ぶ。
- 適合率(Precision)も全く同じなら、閾値が最大のものを選ぶ。
-
②バランスを重視する場合
- F値が全く同じ場合は、閾値が最大のものを選ぶ。
-
③正確な候補を抽出することを重視する場合
- 適合率(Precision) が99%以上の場合が複数ある時は、その中で再現率(Recall)の値が最も高い確信度の閾値を選ぶ。
- 再現率(Recall)が全く同じ場合は、適合率(Precision)が最も高い閾値を選ぶ。
- 適合率(Precision)も全く同じなら、閾値最大のものを選ぶ。
テストデータの評価結果
テストデータの評価結果(右側表)には、次の項目があります。
- ①確信度:AIモデルがどの程度自信を持って推論したかの割合
- ②正解/不正解:学習用データで共通キー項目(目的変数)に指定したデータを推論できたか否か
テストデータの評価結果をCSV出力することもできます。
- ③評価結果を出力
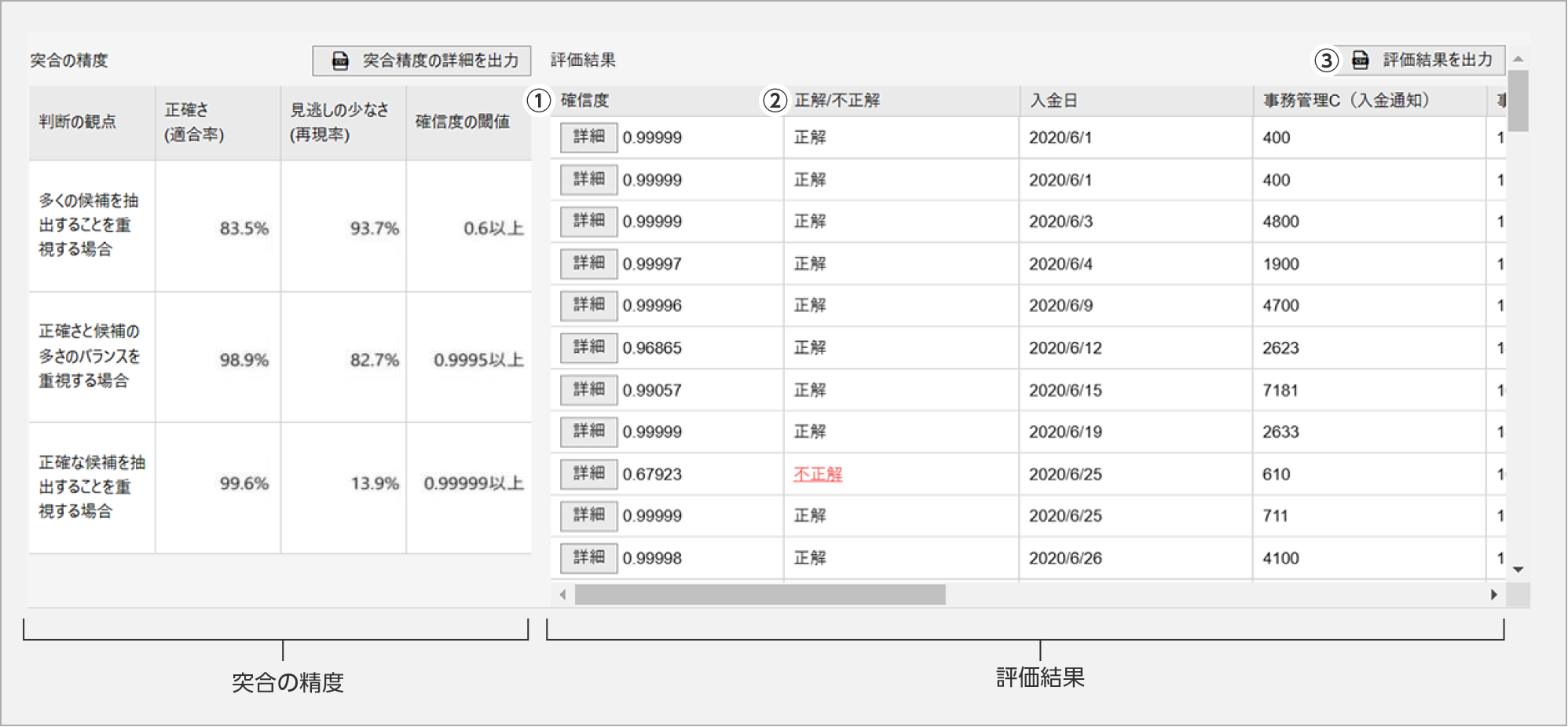
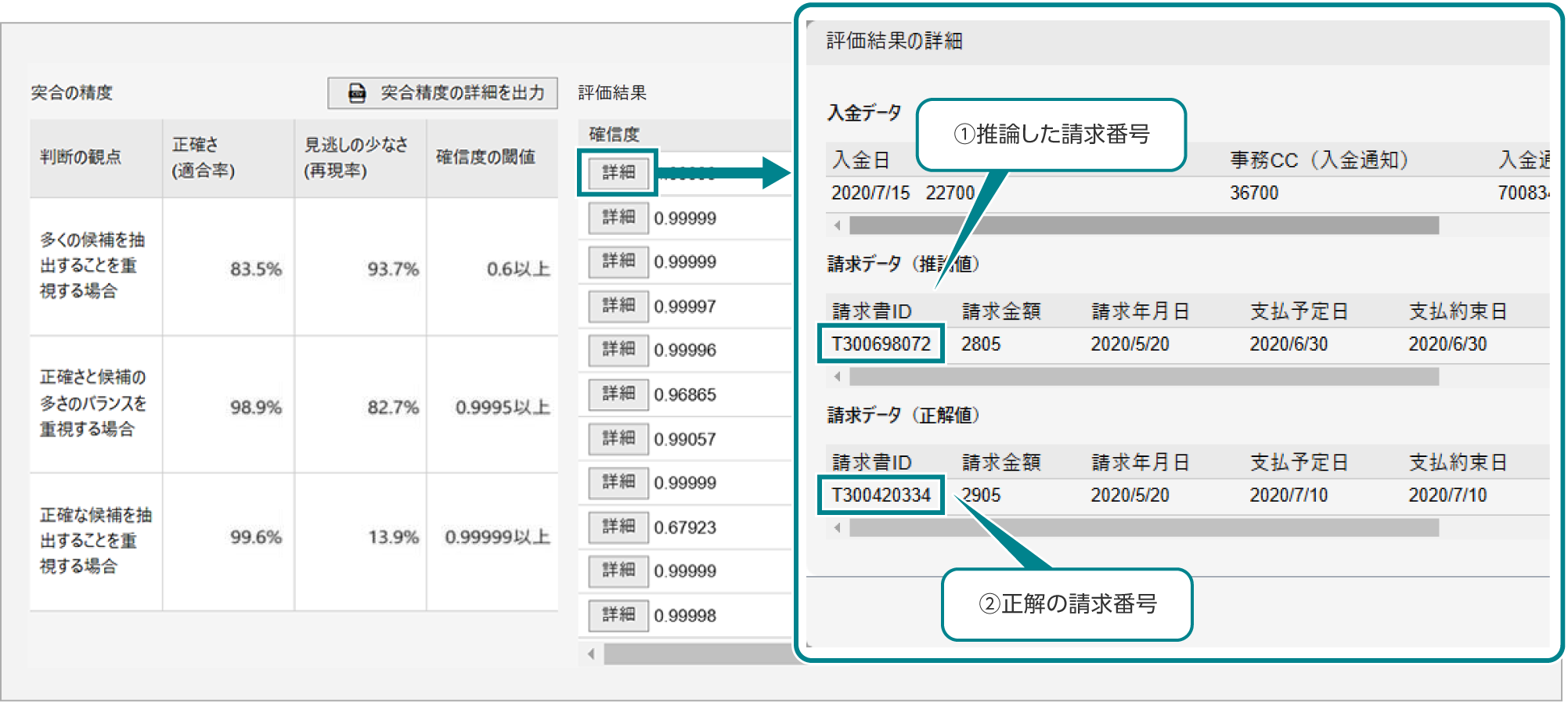
評価結果の詳細の見方
評価結果画面の「詳細」ボタンを押下すると評価結果の詳細が表示されます。
入金請求突合は、請求データと漏れなく突合(完全一致)できれば正解と判定します。
図の例では、①推論した請求データと、②正解の請求データが異なるため不正解。
評価結果のCSVファイルの見方
「評価結果を出力」からCSVをダウンロードします。入金データと推論した請求データの組み合わせで出力されます。
- ①学習結果の評価(先頭2項目)
確信度:AIモデルがどの程度自信を持って推論したかの割合
正解/不正解:学習用データで共通キー項目(目的変数)に指定したデータを推論できたか否か - ②評価結果:AIモデルが推論した請求データ
- ③入金データ:学習用データ
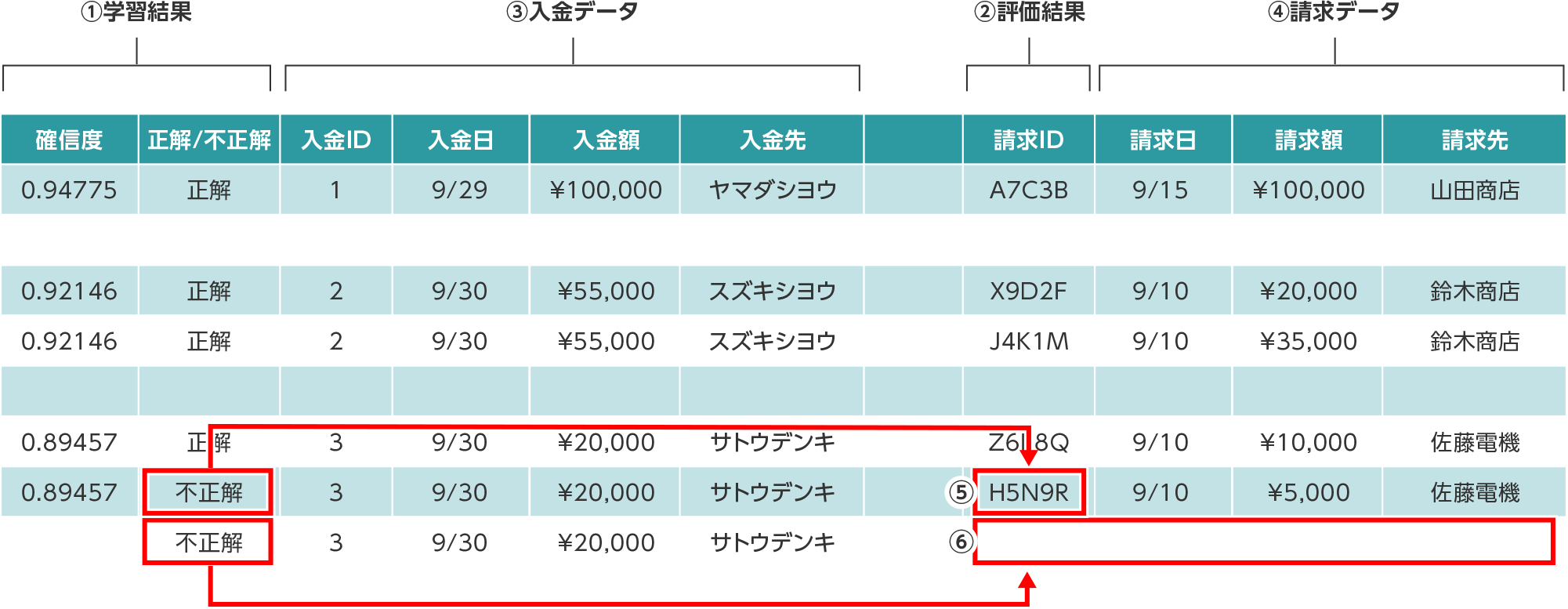
- ④評価結果が正解と異なるため不正解
- ⑤マッチング先を推論できていないため不正解
需要予測の学習結果を確認する
需要予測の評価結果は、3段階スコア、系列ごとの精度一覧、系列の精度と評価結果の詳細、特徴量重要度で確認します。
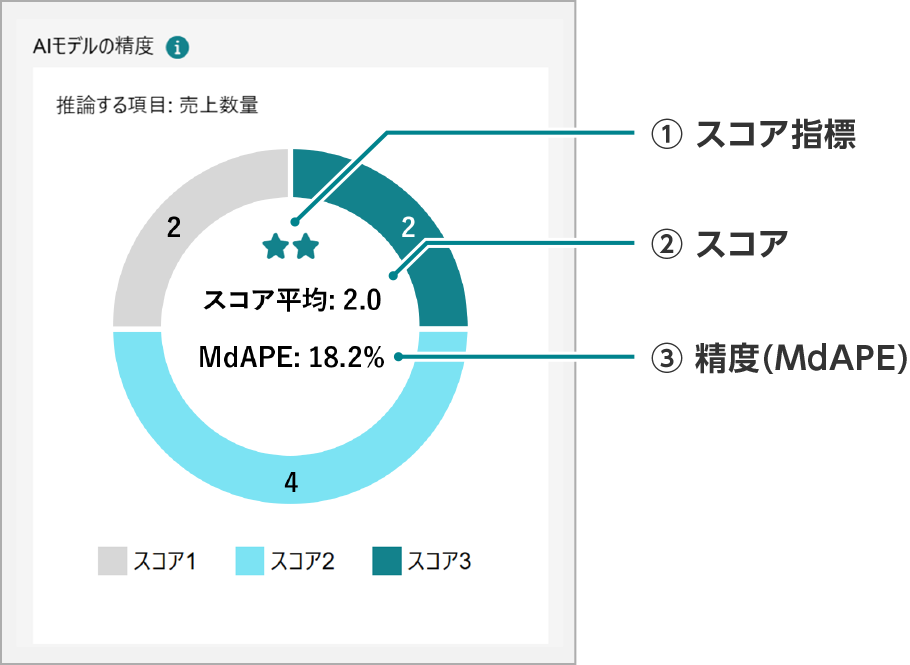
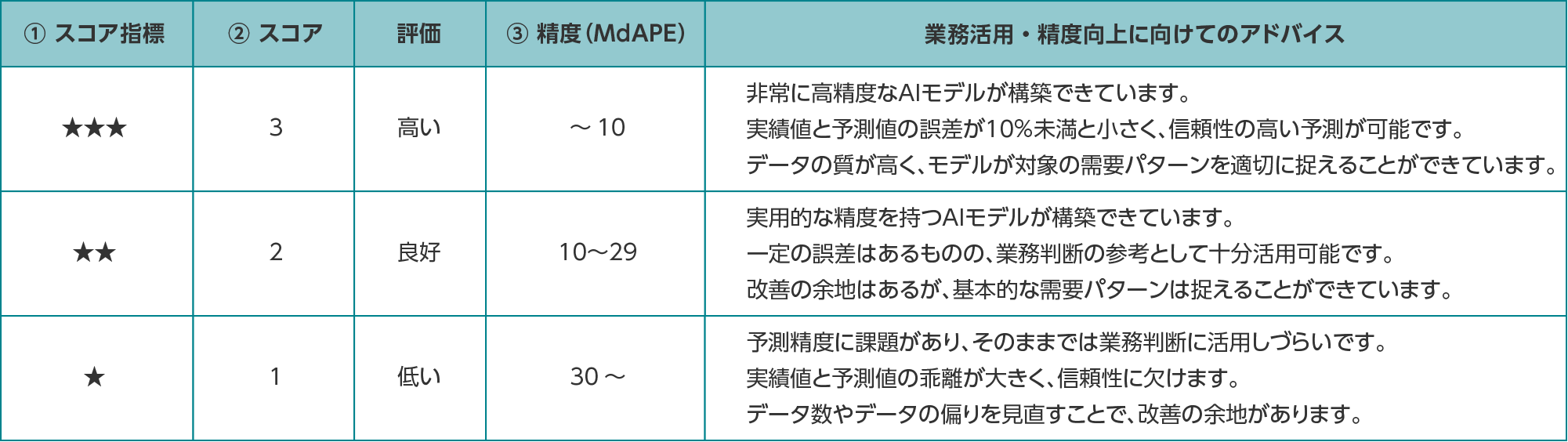
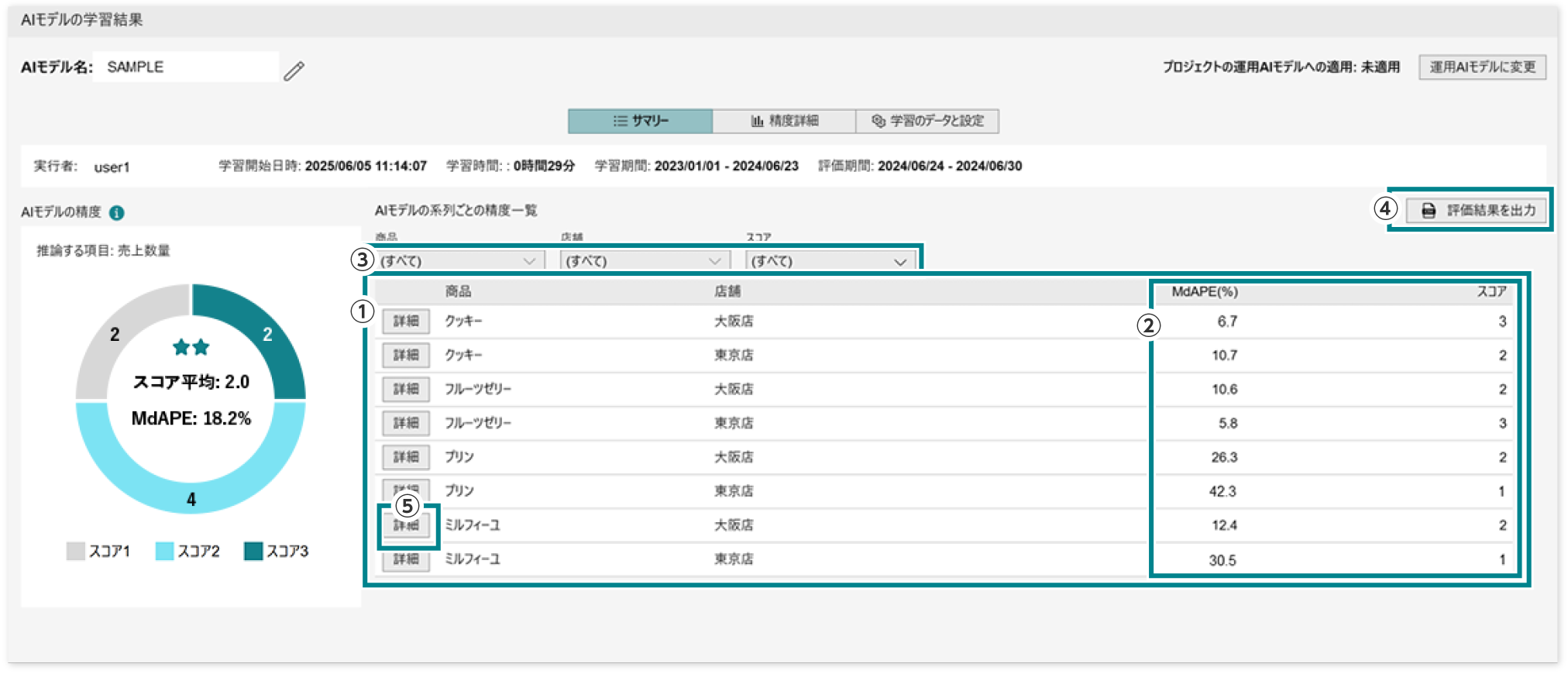
AIモデルの精度
スコアは誤差率中央値(MdAPE)の値をもとにした、AIモデルの性能を示す参考値です。グラフ中の数値は、系列ごとの精度一覧に表示されている各スコアの件数を合計した数を表しています。スコアの件数の分布から、業務に活用できるかどうかの判断や、さらなる性能向上を目指すかどうかの目安にします。
- 精度を向上させたい時:学習結果(AIモデル)を改善する
系列ごとの精度一覧
学習時に設定した系列(商品カテゴリ、店舗、地域など)の組み合わせごとに精度を確認できます。
- ①以下の例では、「商品」と「店舗」の系列があります。
商品:プリン×店舗:東京店のように、それぞれの系列の組み合わせごとに精度が表示されます。 - ②精度はMdAPEとスコアで表します。
- MdAPE:誤差率中央値(MdAPE)は、外れ値の影響を抑えた精度を示す指標です。この値が小さいほど、予測値が実際の値に近いことを示します。
- スコア:MdAPEの値に基づいた予測精度の性能を示す参考値です。詳細:AIモデルの精度
- ③それぞれの系列やスコアで結果を絞り込むことができます。
- ④評価結果をCSV出力することもできます。
- ⑤それぞれの系列の組み合わせの詳細画面を開きます。
→系列の精度と評価結果の詳細へ
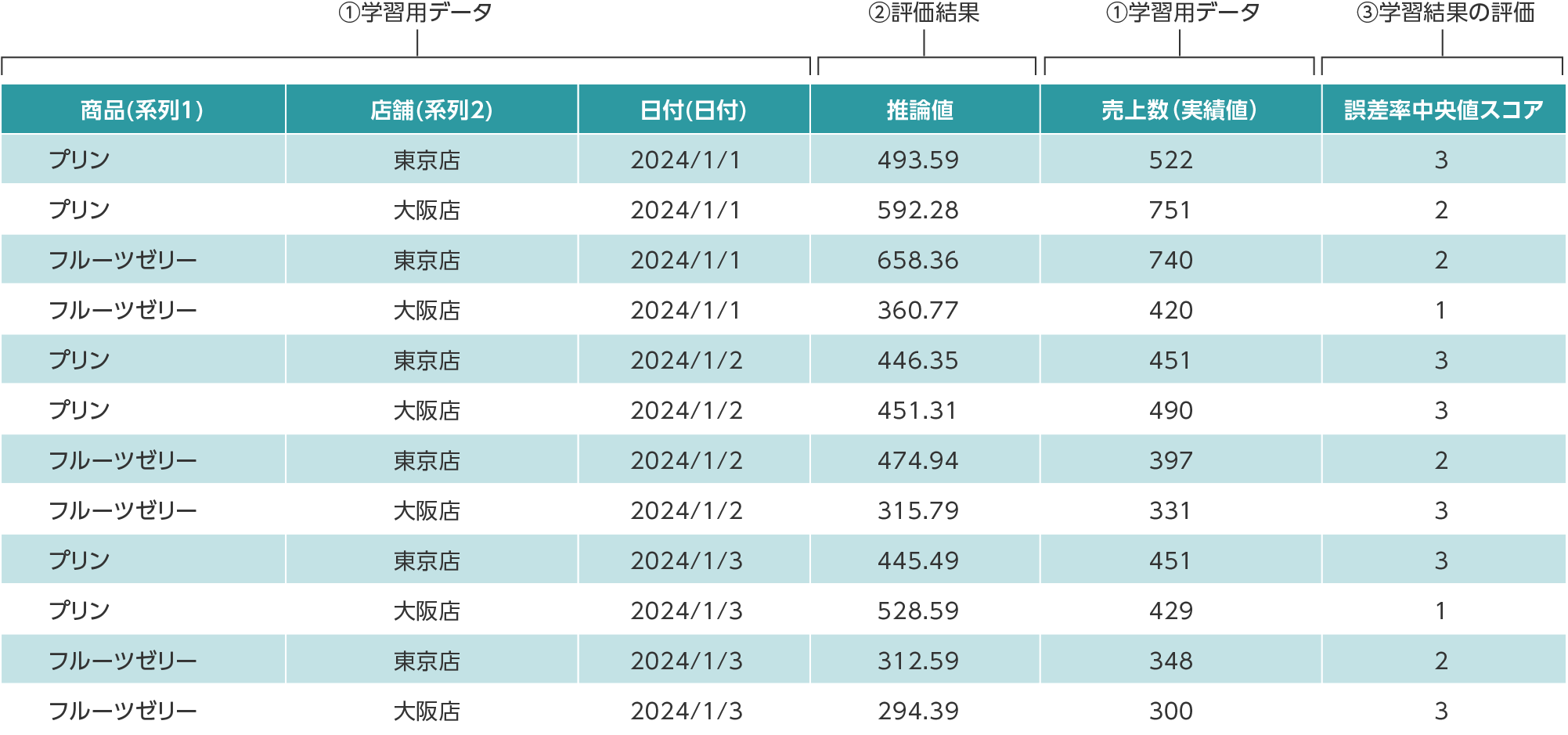
評価結果
評価結果のCSVファイルの見方
- ①学習用データ:学習時に設定した項目
- ②評価結果:AIモデルが推論したデータ
- ③学習結果の評価:誤差率中央値(MdAPE)」の値をもとにした、AIモデルの性能を示す参考値
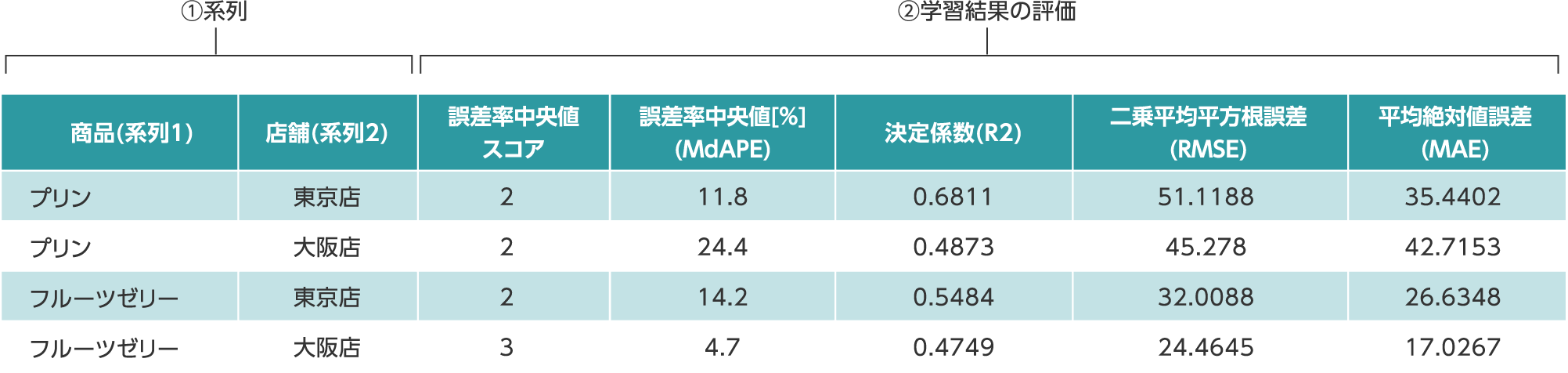
系列ごとの精度一覧のCSVファイルの見方
- ①系列:学習時に設定した系列データ
- ②学習結果の評価:主要スコア
系列の精度と評価結果の詳細
主要スコア
主要スコアは、さまざまな観点でAIモデルの精度を判断するための指標です。


系列の精度と評価結果の詳細
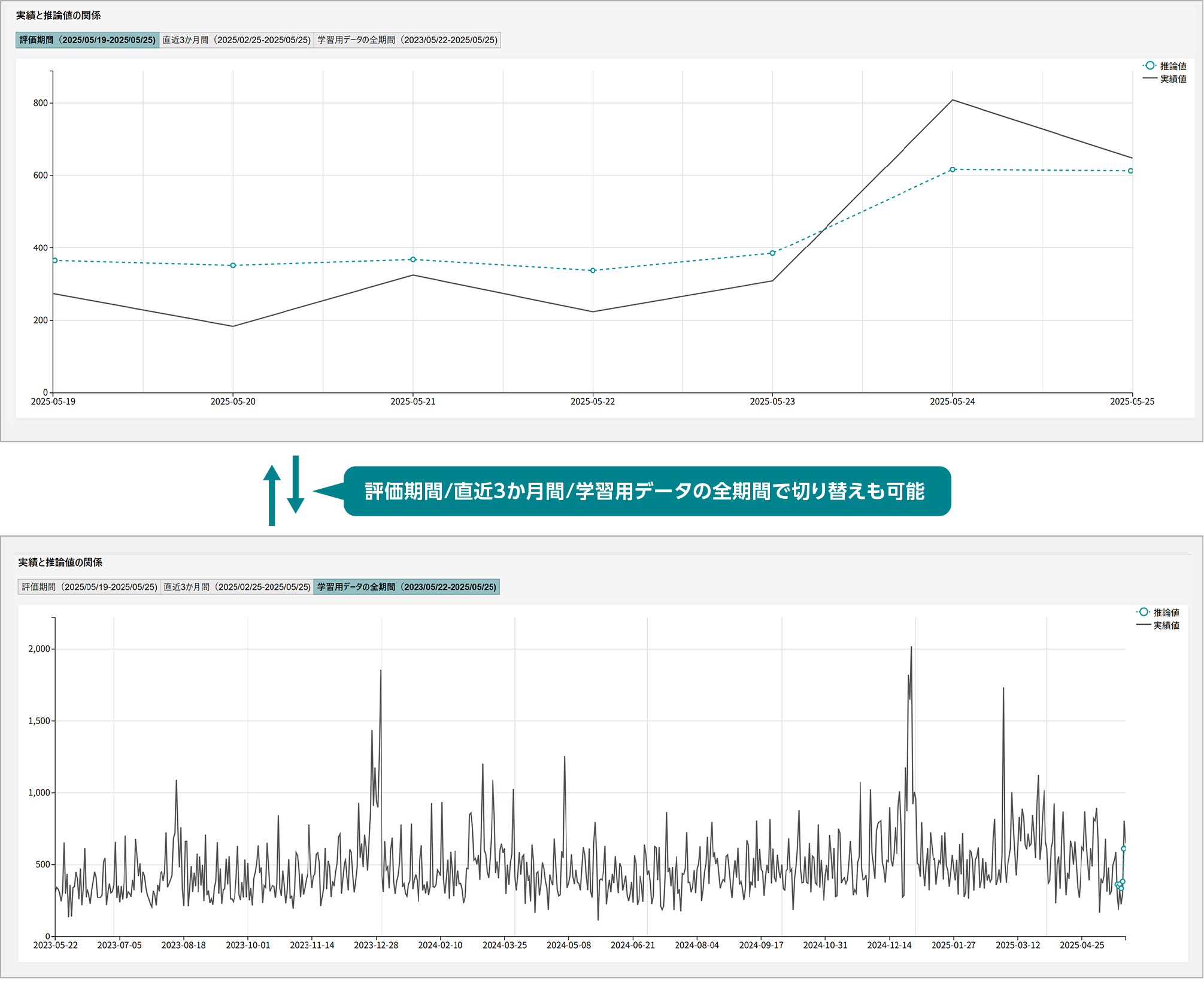
- ①実績値(実際の観測値)と推論値(AIモデルによる予測値)の関係を時系列に沿ったグラフで表示します。
実績値(実線)と推論値(点線)の距離が近く、波形が近似しているほどAIモデルによる予測値が正確であることを表しています。時系列グラフを確認することで、AIモデルの予測精度や特性を視覚的に把握できます。 - ②グラフの表示期間を切り替えることができます。
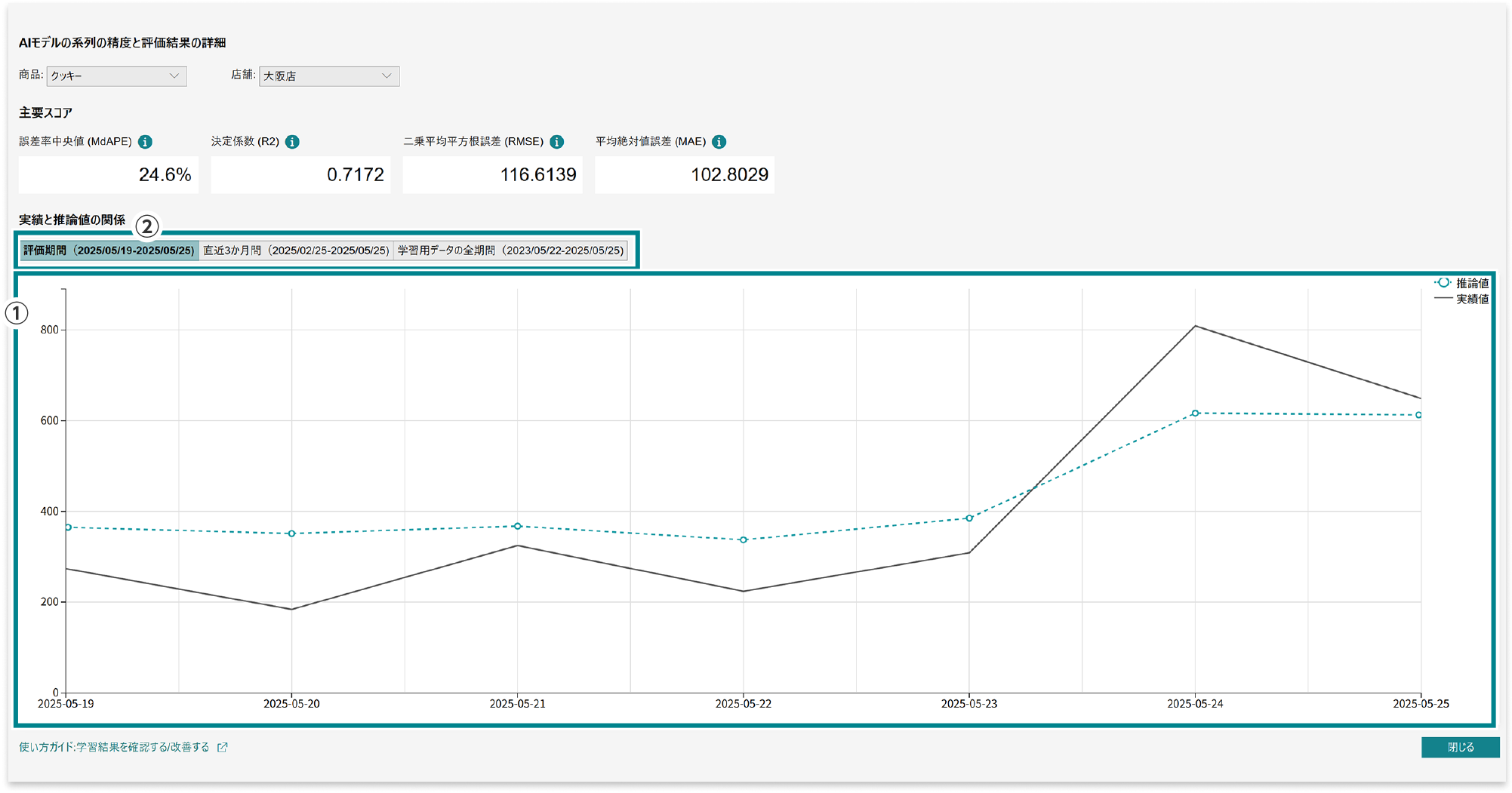
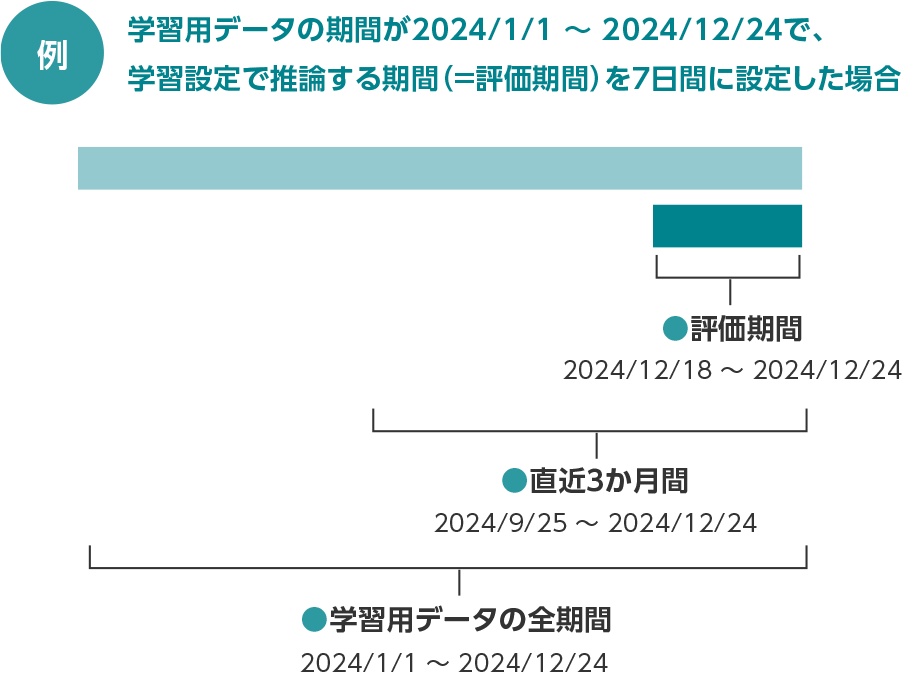
- 評価期間:学習用データの最終日から[推論する期間]分、さかのぼった期間。実績値と推論値の差異を比較しやすい表示です。
- 直近3か月間:学習用データの最終日から3か月さかのぼった期間。
直近3か月の実績値のトレンドと、推論値を比較しやすい表示です。
(学習用データの期間が3か月に満たない場合は表示されません) - 学習用データの全期間:全期間の実績値のトレンドと、推論値を比較しやすい表示です。
時系列グラフでは、青線が実績値、緑線が予測値を表しています。このグラフから以下の点を確認できます。
- 線が近い:青線と緑線が近いほど、予測が正確
- 動きが一致:上がる時は一緒に上がる、下がる時は一緒に下がっていれば良い予測
ポイント:特に重要な時期(繁忙期など)の予測精度に注目しましょう。確認できるポイントとしては以下の点が挙げられます。
- トレンド性:AIモデルが全体的な増加/減少を捉えているか
- 季節性:日ごと・週ごと・月ごと・年ごとなどの周期的なパターンを予測できているか
- ピークと谷の予測精度:需要の急増/急減をどの程度正確に予測できているか
精度詳細
特徴量重要度は、学習用データの説明変数などの特徴量がどの程度重要かを表した数値です。 推論に必要な特徴量であるほど値が大きく、重要度に応じて降順で表示します。
需要予測の特徴量重要度
特徴量について:日付のデータをもとにした周期性(1週間前の値、1か月前の値など)、カレンダー特徴量(曜日、休日など)、気象特徴量(天気、温度など)、説明変数をもとにした特徴量が作成されます。生成された特徴量が重要だった場合、値が表示されます。
説明変数をもとにした特徴量
製造業の需要予測を行う下図の例では、「7日前の数量」や「曜日」、「広告紙面の掲載位置」が重要だと分析されています。この結果が、過去の経験と一致している場合(例:広告紙面のトップに掲載された商品の売り上げが増加するなど)や、新たな発見が含まれている場合(例:特定の曜日に需要が増加するなど)は、学習結果の妥当性を確認して、AIモデルを在庫計画や販促施策に活用できるか判断します。

学習結果(AIモデル)を改善する
プロジェクトのゴール設定に対してAIモデルの精度が足りない場合は、学習用データや学習の設定を見直し、AIモデルの改善を検討します。
学習用データを見直す
データの量は十分か?
- 説明変数(データの項目数)が少なくないか?
一見不要そうだが関与する可能性のある項目は説明変数として加える…①
(特徴量重要度で関連がないことが分かった場合は省いてもよい) - データ数(データの行数)が少なくないか?
多くのデータから規則性を分析するためデータ数が重要…②
手元に複数のデータがある場合は一つのファイルに結合して学習してみる。
【販促用DMのターゲット抽出の例】
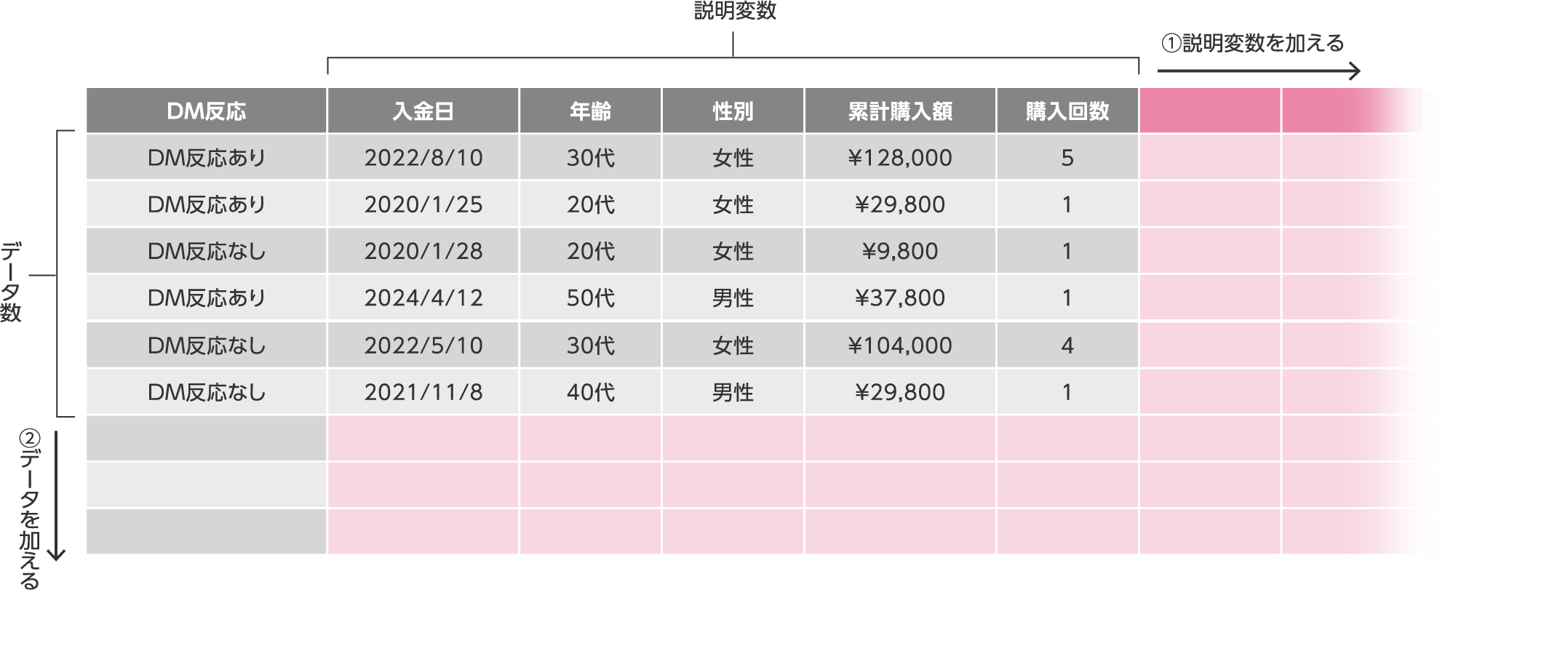
- データ取得時期の偏りがないか?
特異な事象(イベント期間中、コロナ禍など)のデータしかないなど…③
直近のデータで学習する。

分類のケース:データに偏りがないか?
- 目的変数/説明変数の偏り
特定の要素の出現頻度が極端に多い、または少ない…④
出現頻度の少ないカテゴリーのデータを増やす。
カテゴリーの統合・分割をするなどして出現頻度の偏りを調整する。
- カテゴリー型の項目の要素数が100を超える場合は、カテゴリーをまとめて要素数を減らす。
- 目的変数の1カテゴリーに割り当てられるデータ数が10未満の場合、カテゴリーをまとめてデータ数を増やす。
【目的変数の偏りの例】問い合わせ内容を分類したい場合
問い合わせ分類の学習用データで、特定の問い合わせ種別の出現頻度が少ない場合は、他の種別と統合できないか検討し、偏りを調整する。
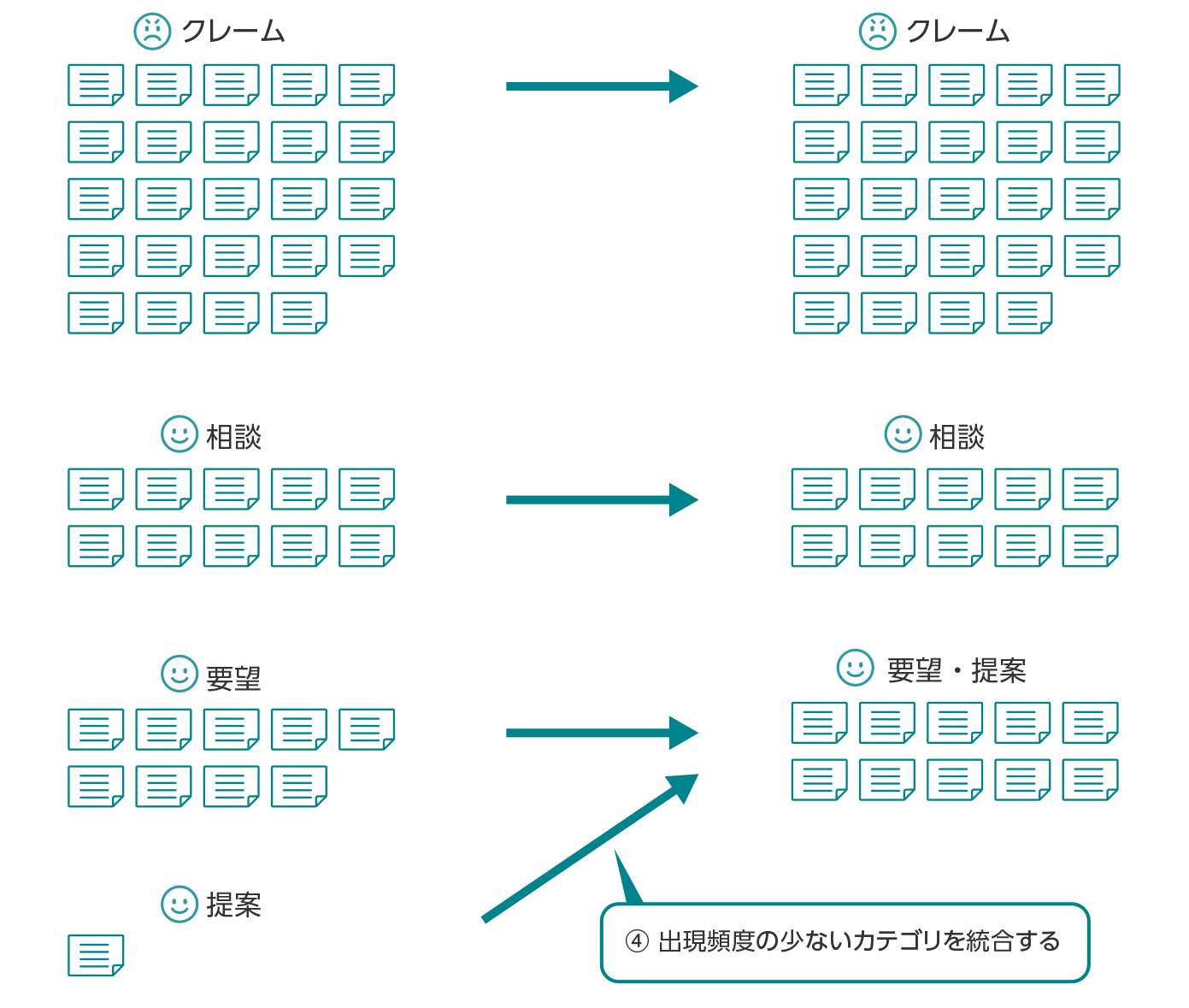
需要予測のケース:データに偏りがないか?
-
特異な事象による偏り
コロナ禍、単発イベントなどによりその期間だけ他と異なる傾向が現れたり、突出した異常データとなっている可能性がある場合は、その期間を含まない期間のデータで学習する。
単発イベント期間などで突出した異常データとなっている場合は、前後の週・月などのデータで代用するなどして調整する。 -
時期・季節による偏り
夏のデータしかない、1ヶ月分のデータしかないなど日付の期間を増やす。 -
系列による偏り
系列によって精度に差がある場合、精度が悪い系列のデータのみで、別途学習する。
すべての系列を一括で学習した場合と比較して、精度が向上する可能性があります。 -
説明変数の偏り
説明変数として追加した項目の値が、時期や季節によって変動しない場合や系列に強く連動している場合は、別の説明変数を加えて学習する。
アナリティクスでデータの設定を変更する
- 参考
- 詳細設定の仕方
①学習する説明変数を選別する
- 学習結果の「特徴量重要度」を確認し、影響の⼩さい説明変数を除外する。
- 明らかに影響しないと判断できる説明変数を除外する。
②データ型を変更する
- 順序尺度の場合には、カテゴリー型ではなく数値型を設定する。
【順序尺度の例】アンケートの評価やランキングで1〜5など大小関係がある場合 - データ型を設定していない場合は設定する。
分類のケースの改善案:
- データ型が数値になっているが、カテゴリーに属する項目がある場合はデータ型をカテゴリーに変更する。
- 短いテキストであっても、文章のデータ型に変更する。(テキストを単語分割して分析します)
データマッチング・入金請求突合のケースの改善案:
- データ対応列とデータ型を設定する。
③データの割合を変更する(デフォルト学習データ:テストデータ=8:2)
- 学習結果が良いのに推論の精度が悪い場合は、テストデータの割合を増やしてみる(8:2→7:3)。
- 学習結果が悪いが、学習データの量を増やせない場合は、学習データの割合を増やしてみる(8:2→9:1)。
④AIモデルのタイプを変更する
- ゴール設定に応じて、見逃しを抑えることを重視したAIモデル、または間違わないことを重視したAIモデルに変更する。
需要予測
- 参考
- 詳細設定の仕方
①学習する系列を変更する
- 学習結果の「特徴量重要度」を確認し、選択した系列の項目の影響が小さい場合、系列選択を外して再度分析する。
②「気象情報の考慮」を変更する
- 学習結果の「特徴量重要度」を確認し、気象情報の影響が小さい場合、「気象情報を考慮しない」を選択し、再度分析する。
③実績値の補完方法を変更する
- 実績値に空白がある場合、実際の運用に合わせて実績値の補完方法を選択する。
- 例えば、販売数量でその日に販売がなかった場合は0、実績はあるがデータが取得できていない場合は最頻値を選択する。

④推論する単位を変更する
- データの集約単位を調整することで精度向上が見込める場合がある。
- 例えば、日ごとから週ごと、月ごとへ推論する単位を変更する。
⑤学習に使用する項目(説明変数)のデータ型を変更する
- すべての値が数値であっても、値を識別するための名前やラベルとして数値を使用している場合は「カテゴリー型」を選択する。

